Süni intellekt modelləri artıq kibertəhlükəsizlik tapşırıqları üçün nəzəri deyil, praktiki baxımdan faydalıdır. Tədqiqatlar və təcrübə qabaqcıl süni intellektin kiberhücumçular üçün alət kimi faydalılığını nümayiş etdirdikcə, biz Claude-un müdafiəçilərə kod və istifadəyə verilmiş sistemlərdəki zəiflikləri aşkar etmək, təhlil etmək və aradan qaldırmaq bacarığını təkmilləşdirməyə sərmayə qoyduq. Bu iş Claude Sonnet 4.5-in yalnız iki ay əvvəl buraxılmış qabaqcıl modelimiz Opus 4.1-ə kod zəifliklərinin kəşfi və digər kiber bacarıqlarda bərabərləşməsinə və ya onu üstələməsinə imkan verdi. Süni intellekti tətbiq etmək və onunla təcrübə aparmaq müdafiəçilərin tempə ayaq uyğunlaşdırması üçün əsas olacaq.
Biz inanırıq ki, hazırda süni intellektin kibertəhlükəsizliyə təsirində dönüş nöqtəsindəyik.
Bir neçə ildir komandamız süni intellekt modellərinin kibertəhlükəsizliklə bağlı imkanlarını diqqətlə izləyir. Əvvəlcə modellərin qabaqcıl və əhəmiyyətli imkanlar baxımından o qədər də güclü olmadığını gördük. Lakin son bir il ərzində dəyişiklik müşahidə etdik. Məsələn:
- Modellərin tarixdəki ən bahalı kiberhücumlardan birini — 2017-ci il Equifax pozuntusunu — simulyasiyada təkrarlaya bildiyini göstərdik.
- Claude-u kibertəhlükəsizlik yarışlarına daxil etdik və o, bəzi hallarda insan komandalarını üstələdi.
- Claude bizə öz kodumuzdakı zəiflikləri kəşf etməyə və buraxılışdan əvvəl onları düzəltməyə kömək etdi.
Bu yayın DARPA AI Cyber Challenge yarışmasında komandalar LLM-lərdən (o cümlədən Claude-dan) istifadə edərək milyonlarla sətir kodu zəifliklər üçün yoxlayan "kiber mühakimə sistemləri" qurdular. Daxil edilmiş zəifliklərdən əlavə, komandalar əvvəllər kəşf edilməmiş, qeyri-sintetik zəiflikləri tapdılar (və bəzən yamadılar). Yarışma mühitindən kənarda, digər qabaqcıl laboratoriyalar da modelləri yeni zəifliklərin kəşfi və bildirilməsi üçün tətbiq edir.
Eyni zamanda, Safeguards işimizin bir hissəsi olaraq, öz platformamızda əməliyyatlarını genişləndirmək üçün süni intellektdən istifadə edən təhdid aktorlarını aşkar etdik və qarşısını aldıq. Safeguards komandamız bu yaxınlarda bir kibercinalinin Claude-dan istifadə edərək əvvəllər bütöv bir komanda tələb edəcək genişmiqyaslı məlumat qəsb sxemi qurduğu "vibe hacking" halını kəşf etdi (və qarşısını aldı). Safeguards həmçinin Claude-un kritik telekommunikasiya infrastrukturunu hədəf alan, Çin APT əməliyyatları ilə uyğun xüsusiyyətlər nümayiş etdirən aktor tərəfindən getdikcə mürəkkəbləşən casusluq əməliyyatlarında istifadəsini aşkar etdi və qarşısını aldı.
Bütün bu sübutlar bizə kiber ekosistemində mühüm bir dönüş nöqtəsində olduğumuzu düşünməyə vadar edir və bundan sonrakı irəliləyiş olduqca sürətli ola bilər və ya istifadə çox tez arta bilər.
Buna görə də, kodu və infrastrukturu qorumaq üçün süni intellektin müdafiə məqsədli istifadəsini sürətləndirmək üçün indi mühüm vaxtdır. Süni intellektdən əldə edilən kiber üstünlüyü hücumçulara və cinayətkarlara güzəştə getməməliyik. Zərərli hücumçuların aşkarlanması və qarşısının alınmasına sərmayə qoymağa davam edərkən, hesab edirik ki, ən genişlənə bilən həll rəqəmsal mühitlərimizi qoruyanları — biznesləri və hökumətləri qoruyan təhlükəsizlik komandaları, kibertəhlükəsizlik tədqiqatçıları və kritik açıq mənbəli proqram təminatının saxlayıcıları kimi — gücləndicirən süni intellekt sistemləri qurmaqdır.
Claude Sonnet 4.5-in buraxılışı ərəfəsində biz məhz bunu etməyə başladıq.
Claude Sonnet 4.5: kiber bacarıqlara vurğu
LLM-lər miqyasca böyüdükcə "emergent abilities" — kiçik modellərdə aşkar olmayan və mütləq model təliminin açıq hədəfi olmayan bacarıqlar — ortaya çıxır. Həqiqətən, Claude-un Capture-the-Flag (CTF) yarışlarında proqram zəifliklərini tapmaq və istismar etmək kimi kibertəhlükəsizlik tapşırıqlarını yerinə yetirmə bacarıqları ümumi faydalı süni intellekt köməkçiləri inkişaf etdirməyin yan məhsulları olub.
Lakin müdafiəçiləri daha yaxşı təchiz etmək üçün yalnız ümumi model tərəqqisinə etibar etmək istəmirik. Süni intellektin və kibertəhlükəsizliyin təkamülündəki bu anın təcililiyinə görə, Claude-u kod zəifliklərinin kəşfi və yamaqlanması kimi əsas bacarıqlarda daha yaxşı etməyə tədqiqatçılar həsr etdik.
Bu işin nəticələri Claude Sonnet 4.5-də əks olunub. O, kibertəhlükəsizliyin bir çox aspektlərində Claude Opus 4.1 ilə müqayisə edilə bilər və ya ondan üstündür, eyni zamanda daha ucuz və sürətlidir.
Qiymətləndirmələrdən sübutlar
Sonnet 4.5-i qurarkən kiçik bir tədqiqat komandası Claude-un kod bazalarında zəiflikləri tapmaq, onları yamaqlamaq və simulyasiya edilmiş təhlükəsizlik infrastrukturunda zəiflikləri yoxlamaq bacarığını artırmağa diqqət yetirdi. Bunları müdafiə aktorları üçün vacib tapşırıqları əks etdirdiyinə görə seçdik. Açıq şəkildə hücum işinə üstünlük verən təkmilləşdirmələrdən — qabaqcıl istismar və ya zərərli proqram yazmaq kimi — qəsdən yayındıq. Modellərin yerləşdirmədən əvvəl etibarsız kodu tapmasına və yerləşdirilmiş kodda zəiflikləri tapıb düzəltməsinə imkan verməyi ümid edirik. Əlbəttə, diqqət yetirmədiyimiz daha çox kritik təhlükəsizlik tapşırıqları var; bu yazının sonunda gələcək istiqamətləri ətraflı şərh edirik.
Tədqiqatımızın təsirlərini yoxlamaq üçün modellərimizi sənaye standartı qiymətləndirmələrdən keçirdik. Bunlar modellər arasında aydın müqayisələr aparmağa, süni intellektin inkişaf sürətini ölçməyə və — xüsusilə yeni, xaricdən hazırlanmış qiymətləndirmələr halında — öz testlərimizə sadəcə öyrətmədiyimizi təmin etmək üçün yaxşı metrika təqdim edir.
Bu qiymətləndirmələri apardıqca diqqət çəkən şeylərdən biri onları dəfələrlə icra etməyin əhəmiyyəti idi. Böyük bir qiymətləndirmə tapşırıqları dəsti üçün hesablama baxımından bahalı olsa belə, bu, istənilən real dünya problemində motivasiyalı hücumçunun və ya müdafiəçinin davranışını daha yaxşı əks etdirir. Bunu etmək təkcə Claude Sonnet 4.5-dən deyil, həm də bir neçə nəsil əvvəlki modellərdən təsirli performans ortaya çıxarır.
Cybench
Bir ildən artıqdır izlədiyimiz qiymətləndirmələrdən biri CTF yarışma tapşırıqlarından götürülmüş benchmark olan Cybench-dir.1 Bu qiymətləndirmədə Claude Sonnet 4.5-dən təkcə Claude Sonnet 4-dən deyil, hətta Claude Opus 4 və 4.1 modellərindən də üstün nəticələr görürük. Ən diqqət çəkən isə, Sonnet 4.5-in hər tapşırıq üçün bir cəhddə əldə etdiyi müvəffəqiyyət ehtimalı, Opus 4.1-in hər tapşırıq üçün on cəhddə əldə etdiyindən yüksəkdir. Bu qiymətləndirmənin bir hissəsi olan tapşırıqlar nisbətən mürəkkəb, uzunmüddətli iş axınlarını əks etdirir. Məsələn, bir tapşırıq şəbəkə trafikinin təhlilini, bu trafikdən zərərli proqramın çıxarılmasını və zərərli proqramın dekompiliyasiya edilib şifrəsinin açılmasını əhatə edirdi. Təcrübəli bir insanın bunu ən azı bir saata, bəlkə də daha uzun müddətə həll edəcəyini təxmin edirik; Claude bunu 38 dəqiqəyə həll etdi.
Claude Sonnet 4.5-ə Cybench qiymətləndirməsində 10 cəhd verdiyimizdə, tapşırıqların 76,5%-ində müvəffəq olur. Bu xüsusilə diqqətəlayiqdir, çünki son altı ayda bu müvəffəqiyyət dərəcəsini iki dəfə artırmışıq (2025-ci ilin fevralında buraxılmış Sonnet 3.7-nin 10 cəhddə yalnız 35,9% müvəffəqiyyət dərəcəsi var idi).
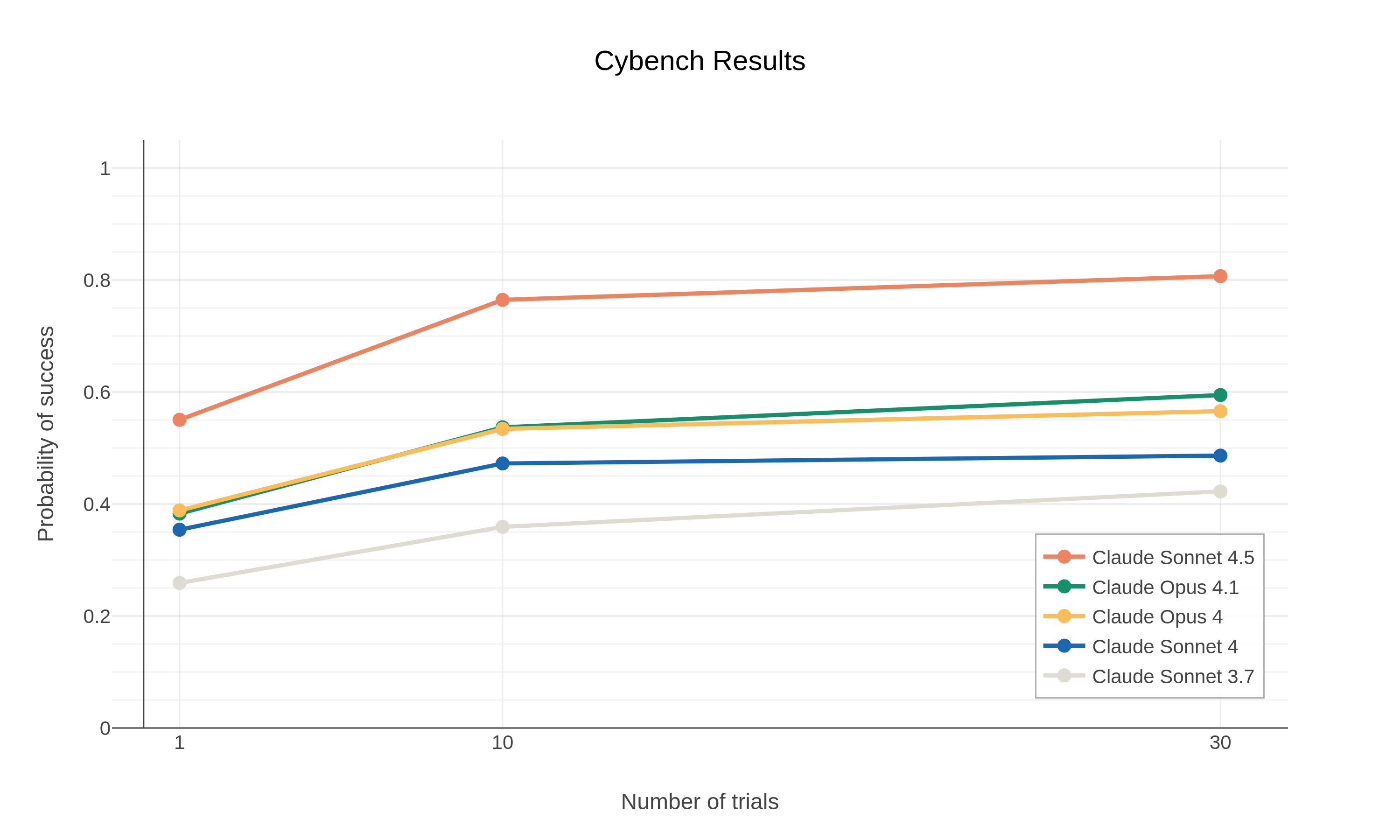 Cybench-də Model Performansı. Claude Sonnet 4.5 k=1, 10 və ya 30 cəhddə bütün əvvəlki modellərdən əhəmiyyətli dərəcədə üstündür, burada müvəffəqiyyət ehtimalı k cəhddən ən azı birinin müvəffəq olduğu problemlərin nisbəti üzrə riyazi gözlənti kimi ölçülür. Qeyd edək ki, bu nəticələr orijinal 40 Cybench probleminin 37-sindən ibarət alt çoxluqdadır, 3 problem tətbiq çətinlikləri səbəbindən xaric edilib.
Cybench-də Model Performansı. Claude Sonnet 4.5 k=1, 10 və ya 30 cəhddə bütün əvvəlki modellərdən əhəmiyyətli dərəcədə üstündür, burada müvəffəqiyyət ehtimalı k cəhddən ən azı birinin müvəffəq olduğu problemlərin nisbəti üzrə riyazi gözlənti kimi ölçülür. Qeyd edək ki, bu nəticələr orijinal 40 Cybench probleminin 37-sindən ibarət alt çoxluqdadır, 3 problem tətbiq çətinlikləri səbəbindən xaric edilib.
CyberGym
Başqa bir xarici qiymətləndirmədə Claude Sonnet 4.5-i agentlərin (1) zəifliyin yüksək səviyyəli təsviri əsasında real açıq mənbəli proqram layihələrində (əvvəllər kəşf edilmiş) zəiflikləri tapma və (2) yeni (əvvəllər kəşf edilməmiş) zəiflikləri kəşf etmə bacarığını qiymətləndirən CyberGym benchmark-ı üzərində qiymətləndirdik.2 CyberGym komandası əvvəllər Claude Sonnet 4-ün ictimai liderlik cədvəlində ən güclü model olduğunu müəyyən etmişdi.
Claude Sonnet 4.5 həm Claude Sonnet 4-dən, həm də Claude Opus 4-dən əhəmiyyətli dərəcədə yaxşı nəticə göstərir. İctimai CyberGym liderlik cədvəli ilə eyni xərc məhdudiyyətlərindən (yəni hər zəiflik üçün $2 LLM API sorğusu limiti) istifadə etdikdə Sonnet 4.5-in 28,9% ilə yeni rekord nəticə əldə etdiyini görürük. Lakin real hücumçular nadir hallarda bu şəkildə məhdudlaşdırılır: onlar hər cəhd üçün $2-dən çox xərclə bir çox hücum cəhdi edə bilərlər. Bu məhdudiyyətləri aradan qaldırıb Claude-a hər tapşırıq üçün 30 cəhd verdikdə, Sonnet 4.5-in proqramların 66,7%-ində zəiflikləri təkrarladığını görürük. Bu yanaşmanın nisbi qiyməti daha yüksək olsa da, mütləq xərc — bir tapşırığı 30 dəfə sınamaq üçün təxminən $45 — olduqca aşağı olaraq qalır.
 *CyberGym-də Model Performansı. Sonnet 4.5 Opus 4.1 daxil olmaqla bütün əvvəlki modelləri üstələyir. Qeyd edək ki, Opus 4.1 daha yüksək qiymətinə görə 1 cəhd ssenarisində digər modellərlə eyni $2 xərc məhdudiyyətinə əməl etmədi.
*CyberGym-də Model Performansı. Sonnet 4.5 Opus 4.1 daxil olmaqla bütün əvvəlki modelləri üstələyir. Qeyd edək ki, Opus 4.1 daha yüksək qiymətinə görə 1 cəhd ssenarisində digər modellərlə eyni $2 xərc məhdudiyyətinə əməl etmədi.
Eyni dərəcədə maraqlı olan Claude Sonnet 4.5-in yeni zəiflikləri kəşf etmə sürətidir. CyberGym liderlik cədvəli Claude Sonnet 4-ün hədəflərin yalnız təxminən 2%-ində zəiflik kəşf etdiyini göstərsə də, Sonnet 4.5 halların 5%-ində yeni zəifliklər kəşf edir. Cəhdi 30 dəfə təkrarlayaraq layihələrin 33%-dən çoxunda yeni zəifliklər kəşf edir.
 CyberGym-də Model Performansı. Sonnet 4.5 yalnız bir cəhddə Sonnet 4-ü yeni zəiflik kəşfində üstələyir və 30 cəhd verildikdə performansını kəskin şəkildə aşır.
CyberGym-də Model Performansı. Sonnet 4.5 yalnız bir cəhddə Sonnet 4-ü yeni zəiflik kəşfində üstələyir və 30 cəhd verildikdə performansını kəskin şəkildə aşır.
Yamaqlanma üzrə əlavə tədqiqatlar
Biz həmçinin Claude-un zəiflikləri düzəldən yamaqlar yaratma və nəzərdən keçirmə bacarığı üzrə ilkin tədqiqatlar aparırıq. Zəifliklərin yamaqlanması onları tapmaqdan daha çətin bir tapşırıqdır, çünki model orijinal funksionallığı dəyişdirmədən zəifliyi aradan qaldıran cərrahi dəyişikliklər etməlidir. Təlimat və ya spesifikasiya olmadan model bu nəzərdə tutulan funksionallığı kod bazasından çıxarmalıdır.
Təcrübəmizdə biz Claude Sonnet 4.5-ə zəifliyin təsviri və proqramın çökdüyü zaman nə etdiyi haqqında məlumat əsasında CyberGym qiymətləndirmə dəstindəki zəiflikləri yamaqlamağı tapşırdıq. Claude-un öz işini qiymətləndirməsi üçün istifadə etdik və təqdim edilmiş yamaqları insan tərəfindən hazırlanmış referans yamaqlarla müqayisə etməyi xahiş etdik. Claude tərəfindən yaradılmış yamaqların 15%-i insan tərəfindən yaradılmış yamaqlarla semantik olaraq ekvivalent hesab edildi. Lakin bu müqayisə əsaslı yanaşmanın mühüm məhdudiyyəti var: zəifliklər çox vaxt bir neçə düzgün yolla düzəldilə bildiyindən, referansdan fərqlənən yamaqlar hələ də düzgün ola bilər ki, bu da qiymətləndirməmizdə yalançı mənfi nəticələrə gətirib çıxarır.
Ən yüksək bal alan yamaqların nümunəsini əl ilə təhlil etdik və onların CyberGym qiymətləndirməsinin əsaslandığı açıq mənbəli proqram təminatına birləşdirilmiş referans yamaqlarla funksional olaraq eyni olduğunu gördük. Bu iş daha geniş tapıntılarımızla uyğun bir nümunə ortaya qoyur: Claude ümumi olaraq təkmilləşdikcə kiberlə bağlı bacarıqlar inkişaf etdirir. İlkin nəticələrimiz göstərir ki, yamaq yaratma — əvvəlki zəiflik kəşfi kimi — fokuslanmış tədqiqatla artırıla biləcək emergent bir bacarıqdır. Növbəti addımımız Claude-u etibarlı yamaq müəllifi və rəyçisi etmək üçün müəyyən etdiyimiz problemləri sistematik şəkildə həll etməkdir.
Etibarlı tərəfdaşlarla məsləhətləşmə
Real dünyada müdafiə təhlükəsizliyi praktikada qiymətləndirmələrimizin əks etdirə biləcəyindən daha mürəkkəbdir. Biz ardıcıl olaraq real problemlərin daha mürəkkəb, tapşırıqların daha çətin olduğunu və tətbiq detallarının çox əhəmiyyətli olduğunu gördük. Buna görə tədqiqatımızın onları necə sürətləndirə biləcəyi barədə rəy almaq üçün müdafiə üçün süni intellektdən istifadə edən təşkilatlarla işləmək vacibdir. Sonnet 4.5-in buraxılışı ərəfəsində modeli zəifliklərin aradan qaldırılması, şəbəkə təhlükəsizliyinin yoxlanılması və təhdid təhlili kimi sahələrdə real problemlərinə tətbiq edən bir sıra təşkilatlarla işlədik.
HackerOne-un Baş Məhsul Direktoru Nidhi Aggarwal belə dedi: "Claude Sonnet 4.5 Hai təhlükəsizlik agentlərimiz üçün orta zəiflik qəbul müddətini 44% azaltdı, eyni zamanda dəqiqliyi 25% artırdı və bu, bizneslərin riskini etibarlı şəkildə azaltmağa kömək etdi." CrowdStrike-ın Data Elmi üzrə Baş Vitse-Prezidenti və Baş Elmi İşçisi Sven Krasser-ə görə, "Claude red teaming üçün güclü perspektiv göstərir — hücumçu taktikalarını öyrənməmizi sürətləndirən yaradıcı hücum ssenariləri yaradır. Bu biliklər endpoint-lər, identifikasiya, bulud, məlumat, SaaS və süni intellekt iş yükləri üzrə müdafiəmizi gücləndirir."
Bu rəylər Claude ilə tətbiqi, müdafiə işinin potensialına inamımızı artırdı.
Növbədə nə var?
Claude Sonnet 4.5 əhəmiyyətli bir təkmilləşdirməni təmsil edir, lakin bilirik ki, onun imkanlarının bir çoxu hələ başlanğıc mərhələsindədir və hələ ki, təhlükəsizlik mütəxəssislərinin və mövcud proseslərin səviyyəsinə çatmır. Modellərimizin müdafiəyə aid imkanlarını təkmilləşdirməyə və platformalarımızı qoruyan təhdid kəşfiyyatı və təxfif tədbirlərini artırmağa davam edəcəyik. Əslində, modellərimizin zərərli kiber davranış üçün sui-istifadəsini tutma bacarığımızı daim təkmilləşdirmək üçün araşdırmalarımız və qiymətləndirmələrimizin nəticələrindən artıq istifadə edirik. Bura tək bir prompt və tamamlamanın xaricində daha böyük mənzərəni başa düşmək üçün təşkilat səviyyəsində ümumiləşdirmə kimi texnikaların istifadəsi daxildir; bu, xüsusilə genişmiqyaslı avtomatlaşdırılmış fəaliyyəti əhatə edən ən zərərli istifadə halları üçün ikili istifadə davranışını zərərli davranışdan ayırmağa kömək edir.
Lakin inanırıq ki, indi mümkün qədər çox təşkilatın süni intellektin təhlükəsizlik mövqelərini necə yaxşılaşdıra biləcəyini araşdırmağa və bu qazancları qiymətləndirmək üçün qiymətləndirmələr qurmağa başlamasının vaxtıdır. Claude Code-da avtomatlaşdırılmış təhlükəsizlik yoxlamaları süni intellektin CI/CD pipeline-ına necə inteqrasiya oluna biləcəyini göstərir. Xüsusilə tədqiqatçılara və komandalara Security Operations Center (SOC) avtomatlaşdırılması, Security Information and Event Management (SIEM) təhlili, təhlükəsiz şəbəkə mühəndisliyi və ya aktiv müdafiə kimi sahələrdə modelləri tətbiq etmə təcrübəsi aparmağa imkan vermək istəyirik. Müdafiə imkanları üçün model qiymətləndirmələri üçün böyüyən üçüncü tərəf ekosisteminin bir hissəsi kimi daha çox qiymətləndirmə görmək və istifadə etmək istərdik.
Lakin müdafiəçilərin xeyrinə qurmaq və tətbiq etmək həllin yalnız bir hissəsidir. Rəqəmsal infrastrukturu daha dayanıqlı etmək və yeni proqram təminatını dizayn baxımından təhlükəsiz etmək — o cümlədən qabaqcıl süni intellekt modellərinin köməyi ilə — barədə söhbətlərə də ehtiyacımız var. Süni intellektin kibertəhlükəsizliyə təsirinin gələcək narahatlığından bu günkü zərurətə keçdiyi bu dövrdə sənaye, hökumət və vətəndaş cəmiyyəti ilə bu müzakirələri səbirsizliklə gözləyirik.
*Bu məqalə əvvəlcə 29 sentyabr 2025-ci il tarixində Frontier Red Team-in bloqunda, red.anthropic.com-da dərc edilmişdir.*