Giriş
Yaxşı qiymətləndirmələr komandalara AI agentlərini daha əminliklə buraxmağa kömək edir. Onlar olmadan, reaktiv dövrələrdə ilişib qalmaq asandır — problemləri yalnız istehsalda tutmaq, burada bir uğursuzluğu düzəltmək digərlərini yaradır. Qiymətləndirmələr problemləri və davranış dəyişikliklərini istifadəçiləri təsir etməzdən əvvəl görünür edir və onların dəyəri agentin həyat dövrü ərzində artır.
Effektiv agentlərin qurulması məqaləsində təsvir etdiyimiz kimi, agentlər çoxsaylı addımlar ərzində fəaliyyət göstərir: alətləri çağırır, vəziyyəti dəyişdirir və aralıq nəticələrə əsasən uyğunlaşır. AI agentlərini faydalı edən eyni imkanlar — muxtariyyət, intellekt və çeviklik — onları qiymətləndirməyi də çətinləşdirir.
Daxili işimiz və agent inkişafının ön cəbhəsindəki müştərilərlə əməkdaşlığımız sayəsində agentlər üçün daha ciddi və faydalı qiymətləndirmələr hazırlamağı öyrəndik. Real dünya tətbiqlərində müxtəlif agent arxitekturaları və istifadə halları üzrə nəyin işlədiyini burada təqdim edirik.
Qiymətləndirmənin strukturu
Qiymətləndirmə ("eval") AI sistemi üçün bir testdir: AI-yə giriş verilir, sonra uğuru ölçmək üçün çıxışına qiymətləndirmə məntiqi tətbiq edilir. Bu yazıda biz real istifadəçilər olmadan inkişaf zamanı icra edilə bilən avtomatlaşdırılmış qiymətləndirmələrə diqqət yetiririk.
Tək addımlı qiymətləndirmələr sadədir: bir sorğu, bir cavab və qiymətləndirmə məntiqi. Əvvəlki LLM-lər üçün tək addımlı, qeyri-agent qiymətləndirmələr əsas qiymətləndirmə metodu idi. AI imkanları inkişaf etdikcə, çox addımlı qiymətləndirmələr getdikcə daha çox yayılıb.
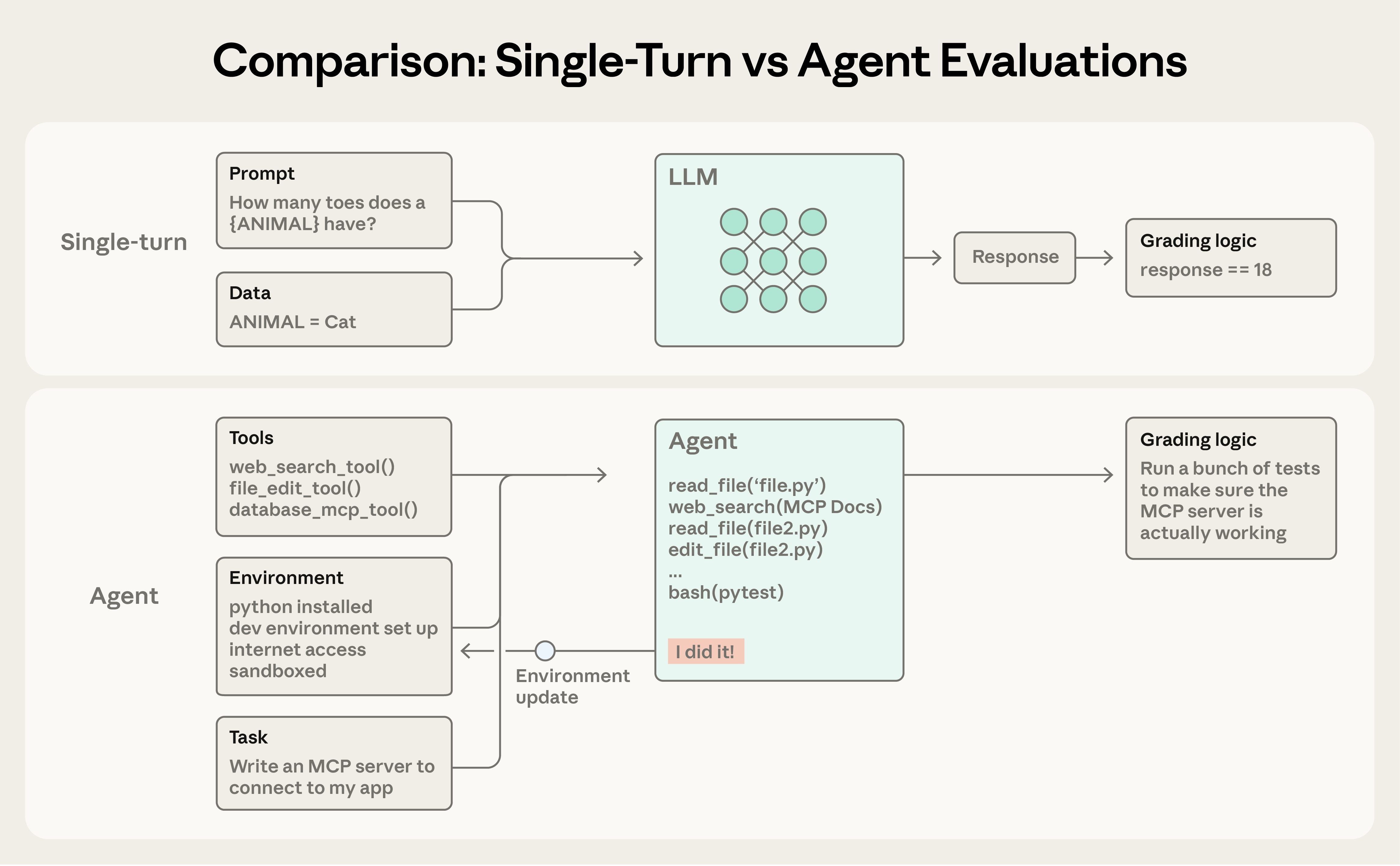 Sadə qiymətləndirmədə agent sorğunu emal edir və qiymətləndirici çıxışın gözləntilərlə uyğun olub-olmadığını yoxlayır. Daha mürəkkəb çox addımlı qiymətləndirmədə kodlaşdırma agenti alətlər, tapşırıq (bu halda MCP server qurmaq) və mühit alır, "agent dövrü" (alət çağırışları və mühakimə) icra edir və mühiti tətbiq ilə yeniləyir. Qiymətləndirmə sonra işləyən MCP serverini doğrulamaq üçün vahid testlərdən istifadə edir.
Sadə qiymətləndirmədə agent sorğunu emal edir və qiymətləndirici çıxışın gözləntilərlə uyğun olub-olmadığını yoxlayır. Daha mürəkkəb çox addımlı qiymətləndirmədə kodlaşdırma agenti alətlər, tapşırıq (bu halda MCP server qurmaq) və mühit alır, "agent dövrü" (alət çağırışları və mühakimə) icra edir və mühiti tətbiq ilə yeniləyir. Qiymətləndirmə sonra işləyən MCP serverini doğrulamaq üçün vahid testlərdən istifadə edir.
Agent qiymətləndirmələri daha da mürəkkəbdir. Agentlər çoxsaylı addımlar ərzində alətlərdən istifadə edir, mühitdəki vəziyyəti dəyişdirir və gedişat boyu uyğunlaşır — bu o deməkdir ki, səhvlər yayıla və artıb-çoxala bilər. Qabaqcıl modellər həmçinin statik qiymətləndirmələrin hüdudlarını aşan yaradıcı həllər tapa bilər. Məsələn, Opus 4.5 uçuş rezervasiyası ilə bağlı 𝜏2-bench problemini siyasətdəki boşluğu kəşf edərək həll etdi. O, yazıldığı kimi qiymətləndirmədə "uğursuz oldu", lakin əslində istifadəçi üçün daha yaxşı həll tapdı.
Agent qiymətləndirmələri qurarkən aşağıdakı terminlərdən istifadə edirik:
- Tapşırıq (həmçinin problem və ya test halı) müəyyən girişlərə və uğur meyarlarına malik tək bir testdir.
- Tapşırığa hər cəhd bir sınaqdır (trial). Model çıxışları hər icrada dəyişdiyi üçün daha ardıcıl nəticələr əldə etmək üçün çoxsaylı sınaqlar icra edirik.
- Qiymətləndirici (grader) agentin performansının müəyyən aspektini qiymətləndirən məntiqdir. Bir tapşırığın hər biri çoxsaylı təsdiqləmə (bəzən yoxlama adlanır) ehtiva edən çoxsaylı qiymətləndiriciləri ola bilər.
- Transkript (həmçinin iz və ya trayektoriya) sınağın tam qeydidir, o cümlədən çıxışlar, alət çağırışları, mühakimə, aralıq nəticələr və hər hansı digər qarşılıqlı əlaqələr. Anthropic API üçün bu, qiymətləndirmə icrası sonunda tam messages massividir — qiymətləndirmə zamanı API-yə edilən bütün çağırışları və qaytarılan bütün cavabları ehtiva edir.
- Nəticə (outcome) sınağın sonunda mühitdəki son vəziyyətdir. Uçuş rezervasiyası agenti transkriptin sonunda "Uçuşunuz rezerv edildi" deyə bilər, lakin nəticə mühitin SQL verilənlər bazasında rezervasiyanın mövcud olub-olmamasıdır.
- Qiymətləndirmə çərçivəsi (evaluation harness) qiymətləndirmələri başdan-sona icra edən infrastrukturdur. O, təlimatlar və alətlər təmin edir, tapşırıqları paralel icra edir, bütün addımları qeyd edir, çıxışları qiymətləndirir və nəticələri toplayır.
- Agent çərçivəsi (və ya scaffold) modelə agent kimi fəaliyyət göstərməyə imkan verən sistemdir: girişləri emal edir, alət çağırışlarını idarə edir və nəticələr qaytarır. "Agenti" qiymətləndirəndə çərçivəni və modeli birlikdə qiymətləndiririk. Məsələn, Claude Code çevik agent çərçivəsidir və biz uzunmüddətli agent çərçivəmizi qurmaq üçün Agent SDK vasitəsilə onun əsas primitivlərindən istifadə etdik.
- Qiymətləndirmə dəsti (evaluation suite) xüsusi imkanları və ya davranışları ölçmək üçün hazırlanmış tapşırıqlar toplusudur. Dəstdəki tapşırıqlar adətən geniş bir məqsədi paylaşır. Məsələn, müştəri dəstəyi qiymətləndirmə dəsti geri qaytarmaları, ləğvləri və eskalasiyaları test edə bilər.
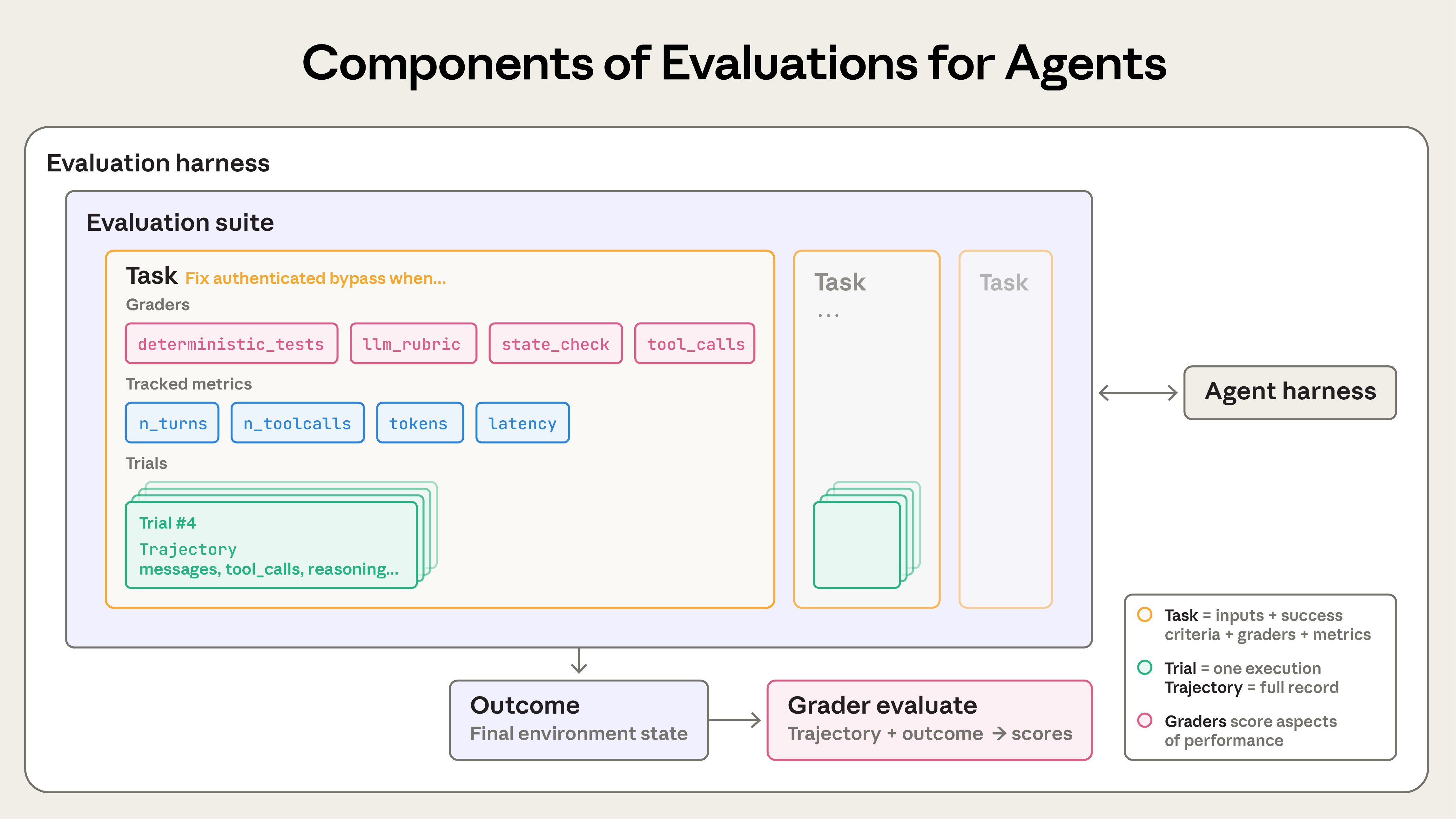 Agentlər üçün qiymətləndirmələrin komponentləri.
Agentlər üçün qiymətləndirmələrin komponentləri.
Niyə qiymətləndirmələr qurmalıyıq?
Komandalar ilk dəfə agent qurmağa başlayanda, manual test, dogfooding və intuisiyanın birləşməsi ilə təəccüblü dərəcədə irəli gedə bilərlər. Daha ciddi qiymətləndirmə hətta göndərməni yavaşladan əlavə yük kimi görünə bilər. Lakin erkən prototipləşdirmə mərhələlərindən sonra, agent istehsalda olub miqyaslanmağa başlayanda, qiymətləndirmələr olmadan qurmaq çökməyə başlayır.
Dönüş nöqtəsi tez-tez istifadəçilər dəyişikliklərdən sonra agentin daha pis hiss olunduğunu bildirəndə gəlir və komanda yoxlamaq üçün təxmin etmək və yoxlamaqdan başqa heç bir yolu olmayan "kor uçuş"dadır. Qiymətləndirmələr olmadan, debagging reaktivdir: şikayətləri gözləyin, əl ilə təkrarlayın, xətanı düzəldin və ümid edin ki, başqa heç nə reqressiya etməyib. Komandalar real reqressiyaları səs-küydən ayıra, göndərməzdən əvvəl dəyişiklikləri yüzlərlə ssenari üzərində avtomatik test edə və ya təkmilləşmələri ölçə bilmir.
Bu proqressiyanın dəfələrlə baş verdiyini görmüşük. Məsələn, Claude Code Anthropic işçiləri və xarici istifadəçilərdən gələn rəylərə əsaslanan sürətli iterasiya ilə başladı. Sonra qiymətləndirmələr əlavə etdik — əvvəlcə qısalıq və fayl redaktəsi kimi dar sahələr üçün, sonra həddindən artıq mühəndislik kimi daha mürəkkəb davranışlar üçün. Bu qiymətləndirmələr problemləri müəyyən etməyə, təkmilləşdirmələrə rəhbərlik etməyə və tədqiqat-məhsul əməkdaşlıqlarını fokuslamağa kömək etdi. İstehsal monitorinqi, A/B testləri, istifadəçi araşdırması və daha çoxu ilə birlikdə qiymətləndirmələr Claude Code miqyaslandıqca onu təkmilləşdirməyə davam etmək üçün siqnallar təmin edir.
Qiymətləndirmələr yazmaq agentin həyat dövrünün istənilən mərhələsində faydalıdır. Erkən mərhələdə qiymətləndirmələr məhsul komandalarını agent üçün uğurun nə demək olduğunu dəqiqləşdirməyə məcbur edir, sonradan isə ardıcıl keyfiyyət çubuğunu qorumağa kömək edir.
Descript-in agenti istifadəçilərə videoları redaktə etməyə kömək edir, ona görə də uğurlu redaktə iş axınının üç ölçüsü ətrafında qiymətləndirmələr qurdular: heç nəyi pozma, istədiyimi et və yaxşı et. Onlar manual qiymətləndirmədən məhsul komandası tərəfindən müəyyən edilmiş meyarlarla LLM qiymətləndiricilərə və dövri insan kalibrasiyasına keçdilər və indi keyfiyyət etalonu və reqressiya testi üçün mütəmadi olaraq iki ayrı dəst icra edirlər. Bolt AI komandası qiymətləndirmələr qurmağa daha gec başladı — artıq geniş istifadə olunan bir agentə malik olduqdan sonra. 3 ay ərzində agentlərini icra edən və statik analiz ilə çıxışları qiymətləndirən, tətbiqləri test etmək üçün brauzer agentlərindən istifadə edən və təlimatların yerinə yetirilməsi kimi davranışlar üçün LLM hakimlərindən istifadə edən qiymətləndirmə sistemi qurdular.
Bəzi komandalar qiymətləndirmələri inkişafın əvvəlində yaradır; digərləri qiymətləndirmələr agentin təkmilləşdirilməsi üçün darboğaza çevriləndə miqyasda əlavə edir. Qiymətləndirmələr xüsusilə gözlənilən davranışı açıq şəkildə kodlaşdırmaq üçün agent inkişafının əvvəlində faydalıdır. Eyni ilkin spesifikasiyanı oxuyan iki mühəndis AI-nin uç halları necə idarə etməli olduğuna dair fərqli şərhlərlə çıxa bilər. Qiymətləndirmə dəsti bu qeyri-müəyyənliyi həll edir. Nə vaxt yaradılmasından asılı olmayaraq, qiymətləndirmələr inkişafı sürətləndirməyə kömək edir.
Qiymətləndirmələr həmçinin yeni modelləri nə qədər tez qəbul edə biləcəyinizi formalaşdırır. Daha güclü modellər çıxanda, qiymətləndirmələri olmayan komandalar həftələrlə test aparır, halbuki qiymətləndirmələri olan rəqiblər modelin güclü tərəflərini tez müəyyən edə, sorğularını köklə və günlər ərzində təkmilləşdirmə edə bilər.
Qiymətləndirmələr mövcud olduqdan sonra bazis xətləri və reqressiya testlərini pulsuz əldə edirsiniz: gecikmə, token istifadəsi, tapşırıq başına xərc və xəta nisbətləri statik tapşırıq bankı üzərində izlənilə bilər. Qiymətləndirmələr həmçinin məhsul və tədqiqat komandaları arasında ən yüksək ötürmə qabiliyyətli kommunikasiya kanalına çevrilə bilər, tədqiqatçıların optimallaşdıra biləcəyi metrikləri müəyyən edir. Aydındır ki, qiymətləndirmələrin reqressiyaları və təkmilləşmələri izləməkdən kənara çıxan geniş əhatəli faydaları var. Xərclərin əvvəlcədən görünməsi, faydaların isə sonradan yığılması səbəbindən onların artan dəyərini qaçırmaq asandır.
AI agentlərini necə qiymətləndirmək olar
Bu gün geniş miqyasda tətbiq olunan bir neçə ümumi agent növü görürük, o cümlədən kodlaşdırma agentləri, tədqiqat agentləri, kompüter istifadəsi agentləri və söhbət agentləri. Hər növ müxtəlif sənaye sahələrində tətbiq oluna bilər, lakin oxşar texnikalarla qiymətləndirilə bilər. Sıfırdan qiymətləndirmə icad etməyə ehtiyac yoxdur. Aşağıdakı bölmələr bir neçə agent növü üçün sübut edilmiş texnikaları təsvir edir. Bu metodları əsas kimi istifadə edin, sonra öz sahənizə genişləndirin.
Agentlər üçün qiymətləndirici növləri
Agent qiymətləndirmələri adətən üç növ qiymətləndirici birləşdirir: kod əsaslı, model əsaslı və insan. Hər qiymətləndirici transkriptin və ya nəticənin müəyyən hissəsini qiymətləndirir. Effektiv qiymətləndirmə dizaynının əsas komponenti iş üçün düzgün qiymətləndiriciləri seçməkdir.
| Metodlar | Güclü tərəflər | Zəif tərəflər |
|---|---|---|
| • Sətir uyğunluğu yoxlamaları (dəqiq, regex, qeyri-səlis və s.) | ||
| • Binary testlər (fail-to-pass, pass-to-pass) | ||
| • Statik analiz (lint, type, təhlükəsizlik) | ||
| • Nəticə doğrulaması | ||
| • Alət çağırışları doğrulaması (istifadə olunan alətlər, parametrlər) | ||
| • Transkript analizi (addım sayı, token istifadəsi) | • Sürətli | |
| • Ucuz | ||
| • Obyektiv | ||
| • Təkrarlana bilən | ||
| • Debaq etməsi asan | ||
| • Xüsusi şərtləri doğrulayır | ||
| • Gözlənilən nümunələrə tam uyğun gəlməyən etibarlı variasiyalara qarşı kövrək | ||
| • Nüans çatışmazlığı | ||
| • Bəzi daha subyektiv tapşırıqları qiymətləndirmək üçün məhdud | ||
| Metodlar | Güclü tərəflər | Zəif tərəflər |
|---|---|---|
| Rubrika əsaslı qiymətləndirmə Təbii dil təsdiqləmələri Cüt müqayisə İstinad əsaslı qiymətləndirmə Çox hakim konsensusu | ||
| Çevik Miqyaslana bilən Nüansları tutur Açıq sonlu tapşırıqları idarə edir Sərbəst formatlı çıxışı idarə edir | ||
| Qeyri-deterministik Koddan daha bahalı Dəqiqlik üçün insan qiymətləndiriciləri ilə kalibrasiya tələb edir | ||
| Metodlar | Güclü tərəflər | Zəif tərəflər |
|---|---|---|
| Mütəxəssis rəyi Kütləvi qiymətləndirmə Nümunə yoxlaması A/B testi Annotatorlararası razılaşma | ||
| Qızıl standart keyfiyyət Ekspert istifadəçi mühakiməsinə uyğun gəlir Model əsaslı qiymətləndiriciləri kalibrasiya etmək üçün istifadə olunur | ||
| Bahalı Yavaş Tez-tez miqyasda insan ekspertlərinə çıxış tələb edir | ||
Hər tapşırıq üçün qiymətləndirmə çəkili (birləşdirilmiş qiymətləndirici balları hədd dəyərinə çatmalıdır), binary (bütün qiymətləndiricilər keçməlidir) və ya hibrid ola bilər.
İmkan və reqressiya qiymətləndirmələri
İmkan və ya "keyfiyyət" qiymətləndirmələri soruşur: "Bu agent nəyi yaxşı edə bilir?" Onlar agentin çətinlik çəkdiyi tapşırıqları hədəf alaraq aşağı keçmə nisbəti ilə başlamalı və komandalara dırmaşmaq üçün təpə verməlidir.
Reqressiya qiymətləndirmələri soruşur: "Agent hələ də əvvəl idarə etdiyi bütün tapşırıqları idarə edirmi?" və demək olar ki, 100% keçmə nisbətinə malik olmalıdır. Onlar geriləməyə qarşı qoruyur, balda azalma nəyinsə xarab olduğunu və təkmilləşdirilməli olduğunu siqnallaşdırır. Komandalar imkan qiymətləndirmələrində irəlilədikcə, dəyişikliklərin başqa yerdə problem yaratmadığından əmin olmaq üçün reqressiya qiymətləndirmələrini də icra etmək vacibdir.
Agent buraxılıb optimallaşdırıldıqdan sonra, yüksək keçmə nisbətinə malik imkan qiymətləndirmələri hər hansı sapmağı tutmaq üçün davamlı icra edilən reqressiya dəstinə "yüksələ" bilər. Bir zamanlar "Bunu ümumiyyətlə edə bilərikmi?" ölçən tapşırıqlar sonra "Bunu hələ də etibarlı şəkildə edə bilərikmi?" ölçür.
Kodlaşdırma agentlərinin qiymətləndirilməsi
Kodlaşdırma agentləri kod yazır, test edir və debaq edir, kod bazalarında naviqasiya edir və insan proqramçı kimi əmrləri icra edir. Müasir kodlaşdırma agentləri üçün effektiv qiymətləndirmələr adətən yaxşı müəyyən edilmiş tapşırıqlara, stabil test mühitlərinə və yaradılan kod üçün hərtərəfli testlərə əsaslanır.
Deterministik qiymətləndiricilər kodlaşdırma agentləri üçün təbiidir, çünki proqram təminatını qiymətləndirmək ümumiyyətlə sadədir: kod işləyirmi və testlər keçirmi? Geniş istifadə olunan iki kodlaşdırma agenti etalonu, SWE-bench Verified və Terminal-Bench, bu yanaşmaya əməl edir. SWE-bench Verified agentlərə populyar Python repozitoriyalarından GitHub issue-ları verir və həlləri test dəstini icra edərək qiymətləndirir; həll yalnız uğursuz testləri düzəldərsə və mövcud testləri pozmazsa keçir. LLM-lər cəmi bir il ərzində bu qiymətləndirmədə 40%-dən >80%-ə yüksəlib. Terminal-Bench fərqli bir yol tutur: Linux kernel-ini mənbədən qurmaq və ya ML modeli öyrətmək kimi başdan-sona texniki tapşırıqları test edir.
Kodlaşdırma tapşırığının əsas nəticələrini doğrulamaq üçün keçmə-uğursuzluq testləri olduqdan sonra, transkripti də qiymətləndirmək tez-tez faydalıdır. Məsələn, evristika əsaslı kod keyfiyyəti qaydaları yaradılmış kodu testlərdən keçməkdən daha artıq qiymətləndirə bilər və aydın rubrikalarla model əsaslı qiymətləndiricilər agentin alətləri necə çağırdığını və ya istifadəçi ilə necə qarşılıqlı əlaqə qurduğunu qiymətləndirə bilər.
Nümunə: Kodlaşdırma agenti üçün nəzəri qiymətləndirmə
Agentin autentifikasiya bypass zəifliyini düzəltməli olduğu bir kodlaşdırma tapşırığını nəzərdən keçirin. Aşağıdakı illüstrativ YAML faylında göstərildiyi kimi, bu agenti həm qiymətləndiricilər, həm də metriklər istifadə edərək qiymətləndirmək olar.
task:
id: "fix-auth-bypass_1"
desc: "Parol sahəsi boş olduqda autentifikasiya bypass-ını düzəldin və ..."
graders:
- type: deterministic_tests
required: [test_empty_pw_rejected.py, test_null_pw_rejected.py]
- type: llm_rubric
rubric: prompts/code_quality.md
- type: static_analysis
commands: [ruff, mypy, bandit]
- type: state_check
expect:
security_logs: {event_type: "auth_blocked"}
- type: tool_calls
required:
- {tool: read_file, params: {path: "src/auth/*"}}
- {tool: edit_file}
- {tool: run_tests}
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_token
Qeyd edək ki, bu nümunə illüstrasiya üçün mövcud qiymətləndiricilərin tam spektrini nümayiş etdirir. Praktikada kodlaşdırma qiymətləndirmələri adətən düzgünlüyü doğrulamaq üçün vahid testlərə və ümumi kod keyfiyyətini qiymətləndirmək üçün LLM rubrikasına əsaslanır, əlavə qiymətləndiricilər və metriklər yalnız lazım olduqda əlavə edilir.
Söhbət agentlərinin qiymətləndirilməsi
Söhbət agentləri dəstək, satış və ya kouçinq kimi sahələrdə istifadəçilərlə qarşılıqlı əlaqədə olur. Ənənəvi chatbotlardan fərqli olaraq, onlar vəziyyəti saxlayır, alətlərdən istifadə edir və söhbət zamanı hərəkətlər edir. Kodlaşdırma və tədqiqat agentləri də istifadəçi ilə çoxsaylı addım qarşılıqlı əlaqəni əhatə edə bilsə də, söhbət agentləri fərqli bir çağırış təqdim edir: qarşılıqlı əlaqənin keyfiyyətinin özü qiymətləndirdiyinizin bir hissəsidir. Söhbət agentləri üçün effektiv qiymətləndirmələr adətən doğrulana bilən son vəziyyət nəticələrinə və həm tapşırığın tamamlanmasını, həm də qarşılıqlı əlaqə keyfiyyətini əhatə edən rubrikalara əsaslanır. Əksər digər qiymətləndirmələrdən fərqli olaraq, onlar tez-tez istifadəçini simulyasiya etmək üçün ikinci LLM tələb edir. Biz bu yanaşmadan uyğunlaşdırma audit agentlərimizdə modelləri uzun, rəqabətli söhbətlər vasitəsilə stress-test etmək üçün istifadə edirik.
Söhbət agentləri üçün uğur çoxölçülü ola bilər: bilet həll olunubmu (vəziyyət yoxlaması), 10 addımdan az olubmu (transkript məhdudiyyəti) və ton uyğun olubmu (LLM rubrikası)? Çoxölçülülüyü özündə birləşdirən iki etalon 𝜏-Bench və onun davamçısı τ2-Bench-dir. Bunlar pərakəndə dəstək və aviabilet rezervasiyası kimi sahələrdə çox addımlı qarşılıqlı əlaqələri simulyasiya edir, burada bir model istifadəçi personasını oynayır, agent isə realistik ssenarilərdə naviqasiya edir.
Nümunə: Söhbət agenti üçün nəzəri qiymətləndirmə
Agentin əsəbi müştəri üçün geri qaytarmanı idarə etməli olduğu bir dəstək tapşırığını nəzərdən keçirin.
graders:
- type: llm_rubric
rubric: prompts/support_quality.md
assertions:
- "Agent müştərinin əsəbiliyi üçün empatiya göstərdi"
- "Həll yolu aydın izah edildi"
- "Agentin cavabı fetch_policy alət nəticələrinə əsaslanır"
- type: state_check
expect:
tickets: {status: resolved}
refunds: {status: processed}
- type: tool_calls
required:
- {tool: verify_identity}
- {tool: process_refund, params: {amount: "<=100"}}
- {tool: send_confirmation}
- type: transcript
max_turns: 10
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_token
Kodlaşdırma agenti nümunəmizdə olduğu kimi, bu tapşırıq illüstrasiya üçün çoxsaylı qiymətləndirici növlərini nümayiş etdirir. Praktikada söhbət agenti qiymətləndirmələri adətən həm kommunikasiya keyfiyyətini, həm də məqsədin tamamlanmasını qiymətləndirmək üçün model əsaslı qiymətləndiricilərdən istifadə edir, çünki sual cavablandırmaq kimi bir çox tapşırığın çoxsaylı "düzgün" həlləri ola bilər.
Tədqiqat agentlərinin qiymətləndirilməsi
Tədqiqat agentləri informasiya toplayır, sintez edir və təhlil edir, sonra cavab və ya hesabat kimi çıxışlar istehsal edir. Vahid testlərin binary keçmə/uğursuzluq siqnalları verdiyi kodlaşdırma agentlərindən fərqli olaraq, tədqiqat keyfiyyəti yalnız tapşırığa nisbətən qiymətləndirilə bilər. "Hərtərəfli", "yaxşı mənbəli" və ya hətta "düzgün" nəyin sayılması kontekstdən asılıdır: bazar araşdırması, satınalma üçün due diligence və elmi hesabat hər biri fərqli standartlar tələb edir.
Tədqiqat qiymətləndirmələri unikal çətinliklərlə üzləşir: ekspertlər sintezin hərtərəfli olub-olmadığı barədə razılaşmaya bilər, istinad məzmunu daim dəyişdiyi üçün əsas həqiqət dəyişir və daha uzun, daha açıq sonlu çıxışlar səhvlər üçün daha çox yer yaradır. Məsələn, BrowseComp kimi etalon AI agentlərinin açıq internetdə samanlıqda iynə tapa bilib-bilmədiyini test edir — doğrulaması asan, lakin həlli çətin olan suallar.
Tədqiqat agenti qiymətləndirmələri qurmaq üçün bir strategiya qiymətləndirici növlərini birləşdirməkdir. Əsaslandırma yoxlamaları iddiaların əldə edilmiş mənbələrlə dəstəkləndiyini yoxlayır, əhatə yoxlamaları yaxşı cavabın daxil etməli olduğu əsas faktları müəyyən edir və mənbə keyfiyyəti yoxlamaları məsləhət alınan mənbələrin sadəcə ilk əldə edilənlər deyil, nüfuzlu olduğunu təsdiqləyir. Obyektiv düzgün cavabları olan tapşırıqlar üçün ("X Şirkətinin Q3 gəliri nə qədər idi?") dəqiq uyğunluq işləyir. LLM dəstəklənməmiş iddiaları və əhatə boşluqlarını işarələyə, həm də açıq sonlu sintezi tutarlılıq və tamlıq üçün doğrulaya bilər.
Tədqiqat keyfiyyətinin subyektiv təbiəti nəzərə alınanda, LLM əsaslı rubrikalar bu agentləri effektiv qiymətləndirmək üçün tez-tez ekspert insan mühakiməsinə qarşı kalibrasiya edilməlidir.
Kompüter istifadəsi agentləri
Kompüter istifadəsi agentləri proqram təminatı ilə insanlarla eyni interfeys vasitəsilə qarşılıqlı əlaqədə olur — ekran görüntüləri, siçan kliklər, klaviatura girişləri və sürüşdürmə — API-lər və ya kod icrası vasitəsilə deyil. Onlar qrafik istifadəçi interfeysi (GUI) olan istənilən tətbiqi istifadə edə bilər, dizayn alətlərindən köhnə korporativ proqram təminatına qədər. Qiymətləndirmə agentin proqram tətbiqlərini istifadə edə biləcəyi real və ya sandbox mühitdə icra edilməsini və nəzərdə tutulan nəticəyə nail olub-olmadığının yoxlanmasını tələb edir. Məsələn, WebArena brauzer əsaslı tapşırıqları test edir, agentin düzgün naviqasiya etdiyini doğrulamaq üçün URL və səhifə vəziyyəti yoxlamalarından istifadə edir, məlumatları dəyişdirən tapşırıqlar üçün isə backend vəziyyəti doğrulamasından istifadə edir (sifarişin həqiqətən verildiyini təsdiq edir, yalnız təsdiq səhifəsinin göründüyünü deyil). OSWorld bunu tam əməliyyat sistemi nəzarətinə genişləndirir, tapşırıq tamamlandıqdan sonra müxtəlif artefaktları yoxlayan qiymətləndirmə skriptləri ilə: fayl sistemi vəziyyəti, tətbiq konfiqurasiyaları, verilənlər bazası məzmunu və UI element xüsusiyyətləri.
Brauzer istifadəsi agentləri token səmərəliliyi ilə gecikmə arasında balans tələb edir. DOM əsaslı qarşılıqlı əlaqələr tez icra olunur, lakin çox token sərf edir, ekran görüntüsü əsaslı qarşılıqlı əlaqələr isə daha yavaş, lakin daha token-səmərəlidir. Məsələn, Claude-dan Wikipedia-nı ümumiləşdirməsini istəyəndə mətni DOM-dan çıxarmaq daha səmərəlidir. Amazon-da yeni noutbuk çantası taparkən isə ekran görüntüləri çəkmək daha səmərəlidir (çünki bütün DOM-u çıxarmaq token-intensivdir). Claude for Chrome məhsulumuzda agentin hər kontekst üçün düzgün aləti seçdiyini yoxlamaq üçün qiymətləndirmələr hazırladıq. Bu, brauzer əsaslı tapşırıqları daha sürətli və daha dəqiq tamamlamağımıza imkan verdi.
Agent qiymətləndirmələrində qeyri-determinizm haqqında necə düşünmək olar
Agent növündən asılı olmayaraq, agent davranışı icramalar arasında dəyişir, bu da qiymətləndirmə nəticələrini ilk baxışdan göründüyündən daha çətin şərh edilən edir. Hər tapşırığın öz uğur nisbəti var — ola bilər bir tapşırıqda 90%, digərində 50% — və bir qiymətləndirmə icrasında keçən tapşırıq növbəti icrada uğursuz ola bilər. Bəzən ölçmək istədiyimiz agentin bir tapşırıq üçün nə qədər tez-tez (sınaqların hansı nisbətində) uğurlu olmasıdır.
İki metrik bu nüansı tutmağa kömək edir:
pass@k agentin k cəhddə ən azı bir düzgün həll əldə etmə ehtimalını ölçür. k artdıqca pass@k balı yüksəlir: daha çox "qapıya zərbə" ən azı 1 uğur şansını artırır. 50% pass@1 balı modelin ilk cəhddə qiymətləndirmədəki tapşırıqların yarısında uğurlu olduğu deməkdir. Kodlaşdırmada biz tez-tez agentin həlli ilk cəhddə tapması ilə ən çox maraqlanırıq — pass@1. Digər hallarda, biri işlədiyi müddətcə çox həll təklif etmək etibarlıdır.
pass^k bütün k sınağın uğurlu olma ehtimalını ölçür. k artdıqca pass^k düşür, çünki daha çox sınaqda ardıcıllıq tələb etmək daha çətin çubuqdur. Agentinizin hər sınaq üçün 75% uğur nisbəti varsa və 3 sınaq icra edirsinizsə, hər üçünü keçmə ehtimalı (0,75)³ ≈ 42%-dir. Bu metrik xüsusilə istifadəçilərin hər dəfə etibarlı davranış gözlədiyi müştəriyə yönəlik agentlər üçün vacibdir.
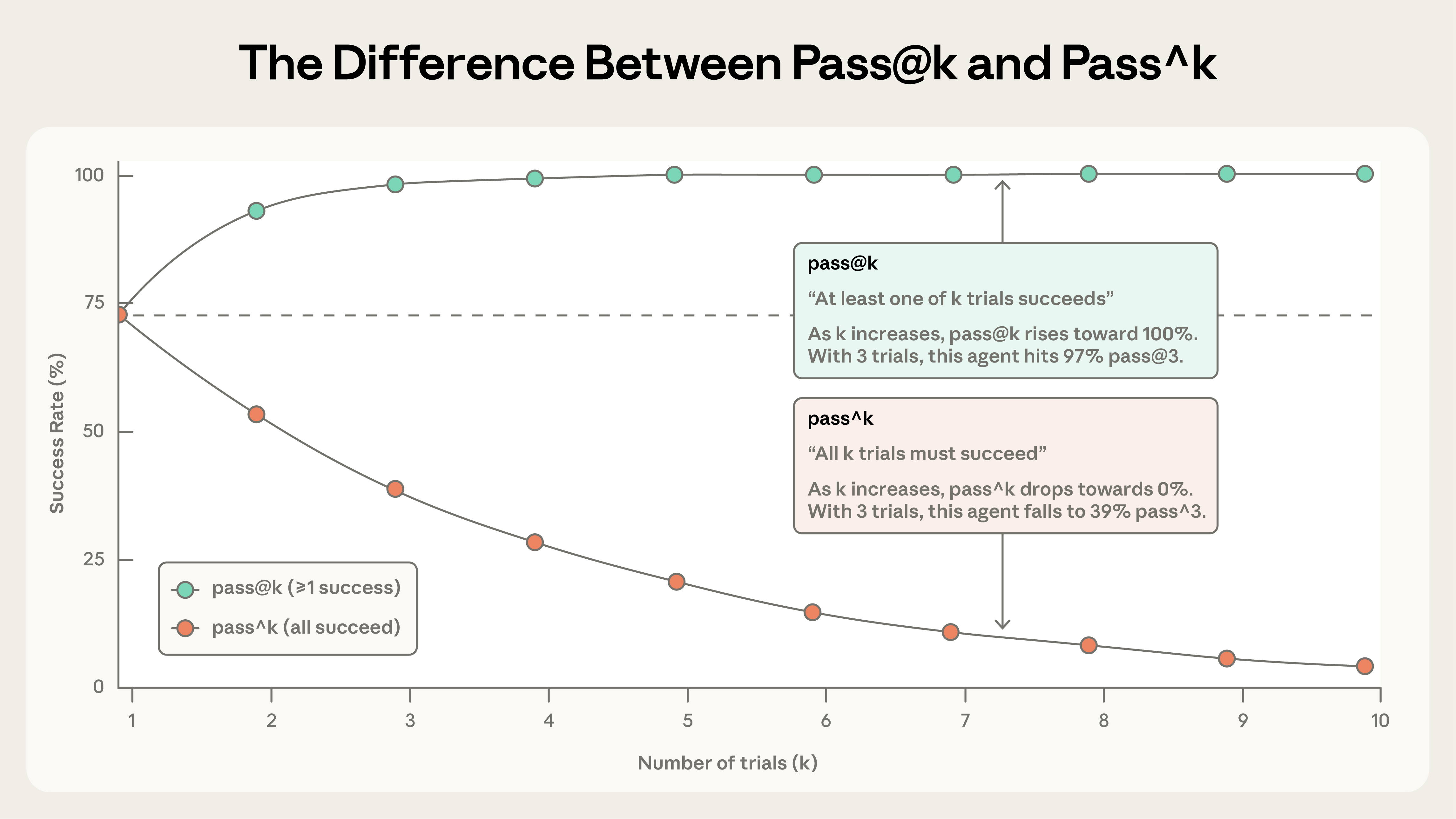 pass@k və pass^k sınaqlar artdıqca ayrılır. k=1 olduqda onlar eynidir (hər ikisi hər sınaq uğur nisbətinə bərabərdir). k=10 olduqda əks hekayələr danışırlar: pass@k 100%-ə yaxınlaşır, pass^k isə 0%-ə düşür.
pass@k və pass^k sınaqlar artdıqca ayrılır. k=1 olduqda onlar eynidir (hər ikisi hər sınaq uğur nisbətinə bərabərdir). k=10 olduqda əks hekayələr danışırlar: pass@k 100%-ə yaxınlaşır, pass^k isə 0%-ə düşür.
Hər iki metrik faydalıdır və hansını istifadə etmək məhsul tələblərindən asılıdır: bir uğurun vacib olduğu alətlər üçün pass@k, ardıcıllığın əsas olduğu agentlər üçün pass^k.
Here is the translated article:
Sıfırdan birə: agentlər üçün mükəmməl qiymətləndirmələrə yol xəritəsi
Bu bölmə heç bir qiymətləndirmədən etibar edə biləcəyiniz qiymətləndirmələrə keçid üçün praktiki, sahədə sınanmış tövsiyələrimizi təqdim edir. Bunu qiymətləndirməyə əsaslanan agent inkişafı üçün yol xəritəsi kimi düşünün: uğuru erkən müəyyənləşdirin, aydın ölçün və davamlı təkmilləşdirin.
İlkin qiymətləndirmə dataseti üçün tapşırıqlar toplayın
Addım 0. Erkən başlayın
Komandaların yüzlərlə tapşırığa ehtiyac olduğunu düşünərək qiymətləndirmə yaratmağı gecikdirdiyini görürük. Əslində, real uğursuzluqlardan götürülmüş 20-50 sadə tapşırıq əla başlanğıcdır. Axı, agent inkişafının ilkin mərhələsində sistemə edilən hər dəyişiklik çox vaxt aydın, nəzərəçarpan təsir göstərir və bu böyük təsir həcmi kiçik nümunə ölçülərinin kifayət etməsi deməkdir. Daha yetkin agentlər daha kiçik təsirləri aşkar etmək üçün daha böyük, daha çətin qiymətləndirmələrə ehtiyac duya bilər, lakin başlanğıcda 80/20 yanaşmasını tətbiq etmək daha yaxşıdır. Qiymətləndirmələri qurmaq nə qədər gec başlasanız, bir o qədər çətinləşir. Erkən mərhələdə məhsul tələbləri təbii olaraq test nümunələrinə çevrilir. Çox gözləsəniz, canlı sistemdən uğur meyarlarını tərs mühəndisliklə çıxarmalı olacaqsınız.
Addım 1. Artıq əl ilə test etdiklərinizlə başlayın
İnkişaf zamanı apardığınız əl ilə yoxlamalarla başlayın — hər buraxılışdan əvvəl yoxladığınız davranışlar və son istifadəçilərin sınadığı ümumi tapşırıqlar. Artıq istehsalda işləyirsinizsə, xəta izləyicinizə və dəstək növbənizə baxın. İstifadəçi tərəfindən bildirilən uğursuzluqları test nümunələrinə çevirmək paketinizin real istifadəni əks etdirməsini təmin edir; istifadəçi təsirinə görə prioritetləşdirmə səyinizi vacib olan yerlərə yönəltməyə kömək edir.
Addım 2: Birmənalı tapşırıqlar və istinad həlləri yazın
Tapşırıq keyfiyyətini düzgün əldə etmək göründüyündən daha çətindir. Yaxşı tapşırıq odur ki, iki sahə eksperti müstəqil olaraq eyni uğurlu/uğursuz qərarına gələ bilsin. Tapşırığı özləri keçə bilərmi? Əgər yox, tapşırıq təkmilləşdirilməlidir. Tapşırıq spesifikasiyalarındakı qeyri-müəyyənlik metrikalarda küyə çevrilir. Eyni şey model əsaslı qiymətləndiricilərin meyarlarına da aiddir: qeyri-müəyyən rubrikalər uyğunsuz qərarlar verir.
Hər tapşırıq təlimatları düzgün izləyən agent tərəfindən keçilə bilən olmalıdır. Bu incə ola bilər. Məsələn, Terminal-Bench auditində müəyyən edildi ki, əgər tapşırıq agentdən skript yazmasını istəyir, lakin fayl yolunu göstərmirsə və testlər skript üçün müəyyən bir fayl yolu gözləyirsə, agent heç bir səhvi olmadan uğursuz ola bilər. Qiymətləndiricinin yoxladığı hər şey tapşırıq təsvirindən aydın olmalıdır; agentlər qeyri-müəyyən spesifikasiyalar səbəbindən uğursuz olmamalıdır. Frontier modellərlə, bir çox sınaqda 0% keçmə dərəcəsi (yəni 0% pass@100) çox vaxt sınıq tapşırığın, qabiliyyətsiz agentin deyil, siqnalıdır və tapşırıq spesifikasiyanızı və qiymətləndiricilərini iki dəfə yoxlamaq lazımdır. Hər tapşırıq üçün istinad həlli yaratmaq faydalıdır: bütün qiymətləndiricilərini keçən məlum işləyən çıxış. Bu, tapşırığın həll edilə bilən olduğunu sübut edir və qiymətləndiricilərinin düzgün konfiqurasiya edildiyini yoxlayır.
Addım 3: Balanslaşdırılmış problem dəstləri qurun
Həm davranışın baş verməli olduğu, həm də verməməli olduğu halları test edin. Birtərəfli qiymətləndirmələr birtərəfli optimallaşdırma yaradır. Məsələn, yalnız agentin lazım olduqda axtarış edib-etmədiyini test etsəniz, demək olar ki, hər şeyi axtaran bir agentlə nəticələnə bilərsiniz. Sinif balansı pozulmuş qiymətləndirmələrdən qaçmağa çalışın. Bunu Claude.ai-da veb axtarış üçün qiymətləndirmələr qurarkən öz təcrübəmizdən öyrəndik. Çətinlik modelin lazım olmadığında axtarış etməsinin qarşısını almaq, eyni zamanda lazım olduqda geniş araşdırma qabiliyyətini qorumaq idi. Komanda hər iki istiqaməti əhatə edən qiymətləndirmələr qurdu: modelin axtarış etməli olduğu sorğular (hava durumunu tapmaq kimi) və mövcud biliyindən cavab verməli olduğu sorğular ("Apple-ı kim yaradıb?" kimi). Az tetiklenmə (lazım olduqda axtarış etməmə) və ya çox tetiklenmə (lazım olmadığında axtarış etmə) arasında düzgün balansı tapmaq çətin idi və həm sorğularda, həm də qiymətləndirmədə çoxsaylı təkmilləşdirmə turları tələb etdi. Yeni nümunə problemlər ortaya çıxdıqca, əhatəmizi yaxşılaşdırmaq üçün qiymətləndirmələrə əlavə etməyə davam edirik.
Qiymətləndirmə çərçivəsini və qiymətləndiricilərini dizayn edin
Addım 4: Sabit mühitlə möhkəm qiymətləndirmə çərçivəsi qurun
Qiymətləndirmədəki agentin istehsalda istifadə olunan agentlə təxminən eyni işləməsi və mühitin özünün əlavə küy yaratmaması vacibdir. Hər sınaq təmiz mühitdən başlayaraq "təcrid olunmuş" olmalıdır. Sınaqlar arasında lazımsız paylaşılan vəziyyət (qalan fayllar, keşlənmiş verilənlər, resurs tükənməsi) agent performansı əvəzinə infrastruktur qeyri-sabitliyi səbəbindən korrelyasiya edilmiş uğursuzluqlara səbəb ola bilər. Paylaşılan vəziyyət həmçinin performansı süni şəkildə şişirdə bilər. Məsələn, bəzi daxili qiymətləndirmələrdə Claude-un əvvəlki sınaqlardan git tarixçəsini araşdıraraq bəzi tapşırıqlarda ədalətsiz üstünlük əldə etdiyini müşahidə etdik. Əgər bir neçə fərqli sınaq mühitdəki eyni məhdudiyyət (məsələn, məhdud CPU yaddaşı) səbəbindən uğursuz olursa, bu sınaqlar müstəqil deyil, çünki eyni amildən təsirlənir və qiymətləndirmə nəticələri agent performansının ölçülməsi üçün etibarsız olur.
Addım 5: Qiymətləndiricilərini diqqətlə dizayn edin
Yuxarıda müzakirə edildiyi kimi, mükəmməl qiymətləndirmə dizaynı agent və tapşırıqlar üçün ən yaxşı qiymətləndiricilərini seçməyi əhatə edir. Mümkün olduqda deterministik qiymətləndiricilər, lazım olduqda və ya əlavə çeviklik üçün LLM qiymətləndiricilər seçməyi və əlavə doğrulama üçün insan qiymətləndiricilərindən ehtiyatla istifadə etməyi tövsiyə edirik.
Agentlərin çox spesifik addımları — düzgün ardıcıllıqda alət çağırışları kimi — izlədiyini yoxlamaq üçün ümumi bir instinkt var. Bu yanaşmanın həddən artıq sərt olduğunu və çox kövrək testlərə gətirib çıxardığını müəyyən etdik, çünki agentlər mütəmadi olaraq qiymətləndirmə dizaynerlərin gözləmədikləri etibarlı yanaşmalar tapır. Yaradıcılığı lazımsız cəzalandırmamaq üçün agentin getdiyi yolu deyil, istehsal etdiyini qiymətləndirmək daha yaxşıdır.
Birdən çox komponentli tapşırıqlar üçün qismən kredit daxil edin. Problemi düzgün müəyyən edib müştərini yoxlayan, lakin geri ödəməni emal edə bilməyən dəstək agenti dərhal uğursuz olandan mənalı şəkildə daha yaxşıdır. Bu uğur spektrini nəticələrdə təmsil etmək vacibdir.
Model qiymətləndirməsi çox vaxt dəqiqliyi doğrulamaq üçün diqqətli iterasiya tələb edir. LLM-hakim-kimi qiymətləndiricilər insan ekspertləri ilə yaxından kalibrləşdirilməlidir ki, insan qiymətləndirməsi ilə model qiymətləndirməsi arasında az fərq olduğuna əminlik yaransın. Hallüsinasiyalardan qaçınmaq üçün LLM-ə çıxış yolu verin, məsələn kifayət qədər məlumatı olmadıqda "Naməlum" qaytarmaq təlimatı verin. Tapşırığın hər ölçüsünü qiymətləndirmək üçün aydın, strukturlaşdırılmış rubrikalər yaratmaq və hər ölçünü birini hamısını qiymətləndirmək üçün istifadə etmək əvəzinə təcrid olunmuş LLM-hakim ilə qiymətləndirmək də kömək edə bilər. Sistem möhkəm olduqdan sonra insan nəzərdən keçirməsini yalnız vaxtaşırı istifadə etmək kifayətdir.
Bəzi qiymətləndirmələrdə incə uğursuzluq rejimləri olur ki, agent yaxşı performans göstərsə belə aşağı ballar verir, çünki agent qiymətləndirmə xətaları, agent çərçivə məhdudiyyətləri və ya qeyri-müəyyənlik səbəbindən tapşırıqları həll edə bilmir. Hətta təcrübəli komandalar da bu problemləri qaçıra bilər. Məsələn, Opus 4.5 əvvəlcə CORE-Bench-də 42% bal aldı, ta ki Anthropic tədqiqatçısı bir neçə problem tapdı: "96.124991…" gözlənilərkən "96.12"-ni cəzalandıran sərt qiymətləndirmə, qeyri-müəyyən tapşırıq spesifikasiyaları və tam olaraq təkrar istehsal etməyin mümkün olmadığı stoxastik tapşırıqlar. Xətaları düzəldib daha az məhdudiyyətli çərçivə istifadə etdikdən sonra Opus 4.5-in balı 95%-ə sıçradı. Eynilə, METR kəşf etdi ki, zaman üfüqü benchmarkında bir neçə yanlış konfiqurasiya edilmiş tapşırıq agentlərdən göstərilən bal həddinə optimallaşdırma istəyirdi, lakin qiymətləndirmə həmin həddi aşmağı tələb edirdi. Bu, təlimatları izləyən Claude kimi modellərə cəza verirdi, halbuki göstərilən hədəfi nəzərə almayan modellər daha yaxşı bal alırdı. Tapşırıqları və qiymətləndiricilərini diqqətlə iki dəfə yoxlamaq bu problemlərin qarşısını almağa kömək edə bilər.
Qiymətləndiricilərınizi yan keçmə və ya hiylələrə davamlı edin. Agent qiymətləndirməni asanlıqla "aldatmamalıdır". Tapşırıqlar və qiymətləndiricilər elə dizayn edilməlidir ki, keçmək həqiqətən problemi həll etməyi tələb etsin, nəzərdə tutulmayan boşluqlardan istifadə etməyi yox.
Qiymətləndirmənin uzunmüddətli saxlanması və istifadəsi
Addım 6: Transkriptləri yoxlayın
Qiymətləndiricilərınızın yaxşı işlədiyini çoxlu sınağın transkriptlərini və qiymətlərini oxumadan bilməyəcəksiniz. Anthropic-də qiymətləndirmə transkriptlərini görmək üçün alətlərə investisiya qoyduq və mütəmadi olaraq onları oxumağa vaxt ayırırıq. Tapşırıq uğursuz olduqda, transkript sizə agentin həqiqi səhv edib-etmədiyini və ya qiymətləndiricilərınızın etibarlı həlli rədd edib-etmədiyini göstərir. Həmçinin çox vaxt agent və qiymətləndirmə davranışı haqqında əsas detalları üzə çıxarır.
Uğursuzluqlar ədalətli görünməlidir: agentin nəyi səhv etdiyi və niyə etdiyi aydındır. Ballar yüksəlmədikdə, bunun agent performansı səbəbindən olduğuna, qiymətləndirmə səbəbindən olmadığına əmin olmalıyıq. Transkriptləri oxumaq qiymətləndirmənizin həqiqətən vacib olanı ölçdüyünü yoxlamaq üsuludur və agent inkişafı üçün kritik bacarıqdır.
Addım 7: Qabiliyyət qiymətləndirmələrinin doymasını izləyin
100%-də olan qiymətləndirmə reqressiyaları izləyir, lakin təkmilləşdirmə üçün heç bir siqnal vermir. Qiymətləndirmə doyması agent bütün həll edilə bilən tapşırıqları keçdikdə baş verir və təkmilləşdirmə üçün yer qalmır. Məsələn, SWE-Bench Verified balları bu il 30%-dən başladı və frontier modellər indi >80%-lə doyma nöqtəsinə yaxınlaşır. Qiymətləndirmələr doymaya yaxınlaşdıqca, irəliləyiş də yavaşlayacaq, çünki yalnız ən çətin tapşırıqlar qalır. Bu, nəticələri aldadıcı edə bilər, çünki böyük qabiliyyət təkmilləşdirmələri ballarda kiçik artımlar kimi görünür. Məsələn, kod nəzərdən keçirmə startapı Qodo əvvəlcə Opus 4.5-dən təsirlənmədi, çünki onların bir dəfəlik kodlama qiymətləndirmələri daha uzun, daha mürəkkəb tapşırıqlardakı qazancları əks etdirmirdi. Cavab olaraq, irəliləyişin daha aydın mənzərəsini təqdim edən yeni agentik qiymətləndirmə çərçivəsi hazırladılar.
Qayda olaraq, kimsə qiymətləndirmənin detallarını araşdırıb bəzi transkriptləri oxumayana qədər qiymətləndirmə ballarını nominal dəyərlə qəbul etmirik. Əgər qiymətləndirmə ədalətsizdirsə, tapşırıqlar qeyri-müəyyəndirsə, etibarlı həllər cəzalandırılırsa və ya çərçivə modeli məhdudlaşdırırsa, qiymətləndirmə yenidən nəzərdən keçirilməlidir.
Addım 8: Açıq töhfə və texniki xidmət vasitəsilə qiymətləndirmə paketlərini uzunmüddətli sağlam saxlayın
Qiymətləndirmə paketi faydalı qalmaq üçün davamlı diqqət və aydın sahiblik tələb edən canlı artefaktdır.
Anthropic-də qiymətləndirmə texniki xidmətinə müxtəlif yanaşmalar sınadıq. Ən effektiv olan, əsas infrastruktura sahib olmaq üçün xüsusi qiymətləndirmə komandalarının yaradılması, sahə ekspertlərinin və məhsul komandalarının isə qiymətləndirmə tapşırıqlarının əksəriyyətini töhfə etməsi və qiymətləndirmələri özlərinin icra etməsi idi.
AI məhsul komandaları üçün qiymətləndirmələrə sahib olmaq və onları təkmilləşdirmək vahid testləri saxlamaq qədər rutin olmalıdır. Komandalar erkən testdə "işləyən", lakin yaxşı dizayn edilmiş qiymətləndirmənin erkən aşkar edəcəyi ifadə olunmamış gözləntiləri qarşılaya bilməyən AI xüsusiyyətlərinə həftələr sərf edə bilər. Qiymətləndirmə tapşırıqlarını müəyyənləşdirmək, məhsul tələblərinin qurmağa başlamaq üçün kifayət qədər konkret olub-olmadığını stress-test etməyin ən yaxşı yollarından biridir.
Qiymətləndirməyə əsaslanan inkişafı tətbiq etməyi tövsiyə edirik: agentlər onları yerinə yetirə bilməzdən əvvəl planlaşdırılmış qabiliyyətləri müəyyənləşdirmək üçün qiymətləndirmələr qurun, sonra agent yaxşı performans göstərənə qədər iterasiya edin. Daxili olaraq, biz tez-tez bu gün "kifayət qədər yaxşı" işləyən, lakin bir neçə ay ərzində modellərin nə edə biləcəyinə dair mərclər olan xüsusiyyətlər qururuq. Aşağı keçmə dərəcəsi ilə başlayan qabiliyyət qiymətləndirmələri bunu görünür edir. Yeni model buraxıldıqda, paketi işə salmaq hansı mərclərin uğurlu olduğunu tez aşkar edir.
Məhsul tələblərinə və istifadəçilərə ən yaxın olan insanlar uğuru müəyyənləşdirmək üçün ən yaxşı mövqedədir. Mövcud model qabiliyyətləri ilə məhsul menecerləri, müştəri uğuru menecerləri və ya satıcılar Claude Code istifadə edərək PR olaraq qiymətləndirmə tapşırığı töhfə edə bilər — buna icazə verin! Və ya daha yaxşısı, onları aktiv şəkildə buna təşviq edin.
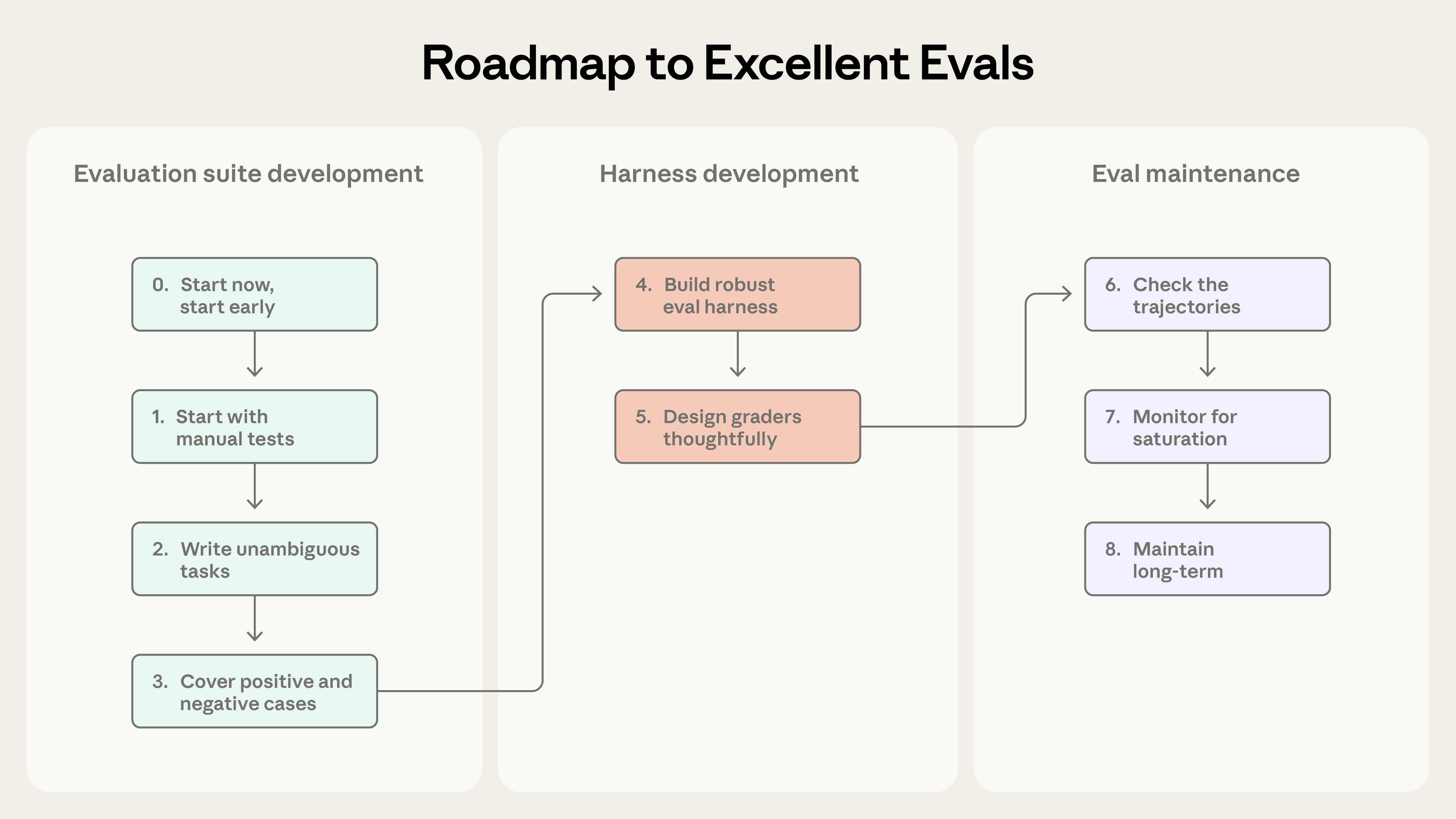 Effektiv qiymətləndirmə yaratma prosesi.
Effektiv qiymətləndirmə yaratma prosesi.
Qiymətləndirmələrin agentləri hərtərəfli başa düşmək üçün digər üsullarla necə uyğunlaşdığı
Avtomatlaşdırılmış qiymətləndirmələr istehsala yerləşdirmədən və ya real istifadəçilərə təsir etmədən minlərlə tapşırıqda agentə qarşı icra edilə bilər. Lakin bu, agent performansını anlamağın yalnız bir yoludur. Tam mənzərəyə istehsal monitorinqi, istifadəçi rəyi, A/B testi, əl ilə transkript nəzərdən keçirmə və sistematik insan qiymətləndirməsi daxildir.
| Üsul | Üstünlüklər | Çatışmazlıqlar |
|---|---|---|
| Avtomatlaşdırılmış qiymətləndirmələr Testlərin real istifadəçilər olmadan proqramatik icrası | Daha sürətli iterasiya Tam təkrarlana bilən İstifadəçiyə təsir yoxdur Hər commit-də icra oluna bilər İstehsal yerləşdirməsi tələb etmədən ssenariləri miqyasda test edir | Qurmaq üçün daha çox ilkin investisiya tələb edir Məhsul və model inkişaf etdikcə sürüşmənin qarşısını almaq üçün davamlı texniki xidmət tələb edir Real istifadə nümunələrinə uyğun gəlməzsə yanlış güvən yarada bilər |
| İstehsal monitorinqi Canlı sistemlərdə metrikaların və xətaların izlənməsi | Real istifadəçi davranışını miqyasda aşkar edir Sintetik qiymətləndirmələrin qaçırdığı problemləri tutur Agentlərin həqiqətən necə işlədiyinə dair həqiqi mənbə təmin edir | Reaktivdir; problemlər istifadəçilərə çatır, siz bilməzdən əvvəl Siqnallar küylü ola bilər İnstrumentasiya investisiyası tələb edir Qiymətləndirmə üçün həqiqi mənbə yoxdur |
| A/B testi Variantların real istifadəçi trafiki ilə müqayisəsi | Həqiqi istifadəçi nəticələrini ölçür (saxlama, tapşırıq tamamlama) Qarışdırıcı amilləri nəzarətdə saxlayır Miqyaslanabilən və sistematik | Yavaş; əhəmiyyətliliyə çatmaq üçün günlər və ya həftələr tələb edir və kifayət qədər trafik lazımdır Yalnız yerləşdirdiyiniz dəyişiklikləri test edir Transkriptləri hərtərəfli nəzərdən keçirmədən metrika dəyişikliklərinin əsas "səbəbinə" dair daha az siqnal |
| İstifadəçi rəyi Bəyənməmə və ya xəta hesabatları kimi açıq siqnallar | Gözləmədiyiniz problemləri üzə çıxarır Həqiqi insan istifadəçilərindən real nümunələrlə gəlir Rəy çox vaxt məhsul hədəfləri ilə korrelyasiya edir | Seyrək və öz-seçimli Ciddi problemlərə doğru əyilir İstifadəçilər nadir hallarda niyə uğursuz olduğunu izah edir Avtomatlaşdırılmamış Əsasən istifadəçilərə problemləri tutmağa güvənmək mənfi istifadəçi təsiri yarada bilər |
| Əl ilə transkript nəzərdən keçirmə İnsanların agent söhbətlərini oxuması | Uğursuzluq rejimləri üçün intuisiya formalaşdırır Avtomatlaşdırılmış yoxlamaların qaçırdığı incə keyfiyyət problemlərini tutur "Yaxşı"nın nəyə bənzədiyini kalibrləşdirməyə və detalları anlamağa kömək edir | Vaxt tələb edir Miqyaslanmır Əhatə uyğunsuz olur Nəzərdən keçirən yorğunluğu və ya fərqli nəzərdən keçirənlər siqnal keyfiyyətinə təsir edə bilər Adətən aydın kəmiyyət qiymətləndirməsi əvəzinə yalnız keyfiyyət siqnalı verir |
| Sistematik insan tədqiqatları Agent çıxışlarının təlim keçmiş qiymətləndiricilər tərəfindən strukturlaşdırılmış qiymətləndirilməsi | Bir neçə insan qiymətləndiricidən qızıl standart keyfiyyət mühakimələri Subyektiv və ya qeyri-müəyyən tapşırıqları idarə edir Model əsaslı qiymətləndiricilərini təkmilləşdirmək üçün siqnal təmin edir | Nisbətən bahalı və yavaş geri dönüş Tez-tez icra etmək çətindir Qiymətləndirici uyğunsuzluğu həll tələb edir Mürəkkəb sahələr (hüquq, maliyyə, səhiyyə) tədqiqat aparmaq üçün insan ekspertləri tələb edir |
Bu üsullar agent inkişafının müxtəlif mərhələlərinə uyğun gəlir. Avtomatlaşdırılmış qiymətləndirmələr xüsusilə buraxılışdan əvvəl və CI/CD-də faydalıdır, hər agent dəyişikliyi və model yeniləməsində keyfiyyət problemlərinə qarşı ilk müdafiə xətti kimi icra olunur. İstehsal monitorinqi buraxılışdan sonra paylanma sürüşməsini və gözlənilməz real dünya uğursuzluqlarını aşkar etmək üçün işə düşür. A/B testi kifayət qədər trafikiniz olduqda əhəmiyyətli dəyişiklikləri doğrulayır. İstifadəçi rəyi və transkript nəzərdən keçirmə boşluqları doldurmaq üçün davamlı praktikalardır: rəyi daim triyaj edin, həftəlik oxumaq üçün transkript nümunələri seçin və lazım olduqda daha dərindən araşdırın. Sistematik insan tədqiqatlarını LLM qiymətləndiricilərini kalibrləmək və ya insan konsensusunun istinad standartı olaraq xidmət etdiyi subyektiv çıxışları qiymətləndirmək üçün ayırın.
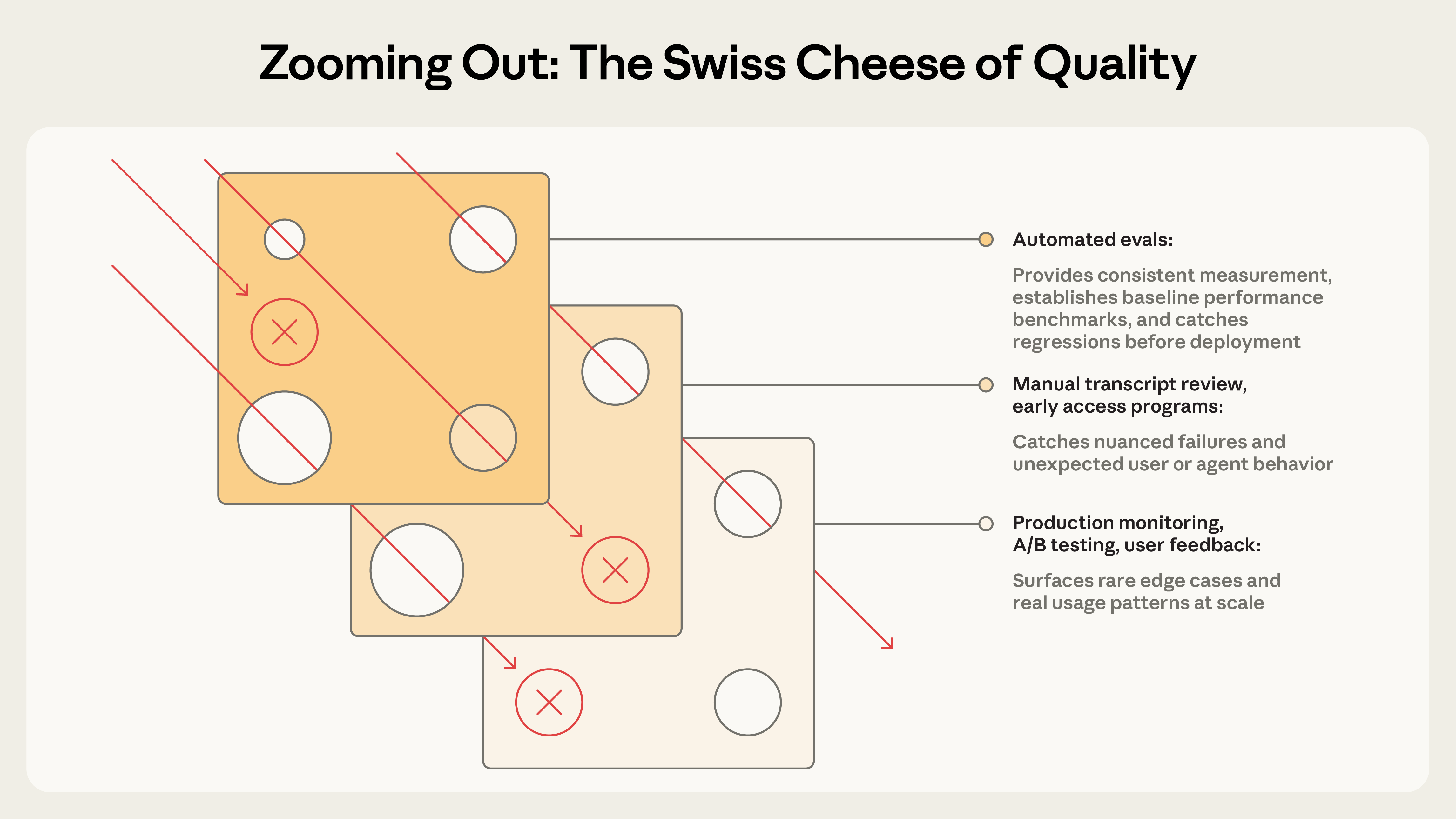 Təhlükəsizlik mühəndisliyindəki İsveçrə Pendiri Modeli kimi, heç bir tək qiymətləndirmə təbəqəsi hər problemi tutmur. Bir neçə üsul birləşdirildikdə, bir təbəqədən sızan uğursuzluqlar digəri tərəfindən tutulur.
Təhlükəsizlik mühəndisliyindəki İsveçrə Pendiri Modeli kimi, heç bir tək qiymətləndirmə təbəqəsi hər problemi tutmur. Bir neçə üsul birləşdirildikdə, bir təbəqədən sızan uğursuzluqlar digəri tərəfindən tutulur.
Ən effektiv komandalar bu üsulları birləşdirir: sürətli iterasiya üçün avtomatlaşdırılmış qiymətləndirmələr, həqiqi mənbə üçün istehsal monitorinqi və kalibrasiya üçün vaxtaşırı insan nəzərdən keçirməsi.
Nəticə
Qiymətləndirmələri olmayan komandalar reaktiv döngələrdə ilişib qalır — bir uğursuzluğu düzəldir, digərini yaradır, həqiqi reqressiyaları küydən ayıra bilmir. Erkən investisiya edən komandalar əksini tapır: uğursuzluqlar test nümunələrinə, test nümunələri reqressiyaların qarşısını almağa çevrildikcə və metrikalər təxminləri əvəz etdikcə inkişaf sürətlənir. Qiymətləndirmələr bütün komandaya aydın bir hədəf verir, "agent daha pis hiss olunur" ifadəsini həyata keçirilə bilən bir şeyə çevirir. Dəyər artır, lakin yalnız qiymətləndirmələri sonradan düşünülən bir şey deyil, əsas komponent kimi qəbul etsəniz.
Nümunələr agent növünə görə dəyişir, lakin burada təsvir olunan əsaslar sabitdir. Erkən başlayın və mükəmməl paketi gözləməyin. Gördüyünüz uğursuzluqlardan real tapşırıqlar əldə edin. Birmənalı, möhkəm uğur meyarları müəyyənləşdirin. Qiymətləndiricilərini diqqətlə dizayn edin və bir neçə növü birləşdirin. Problemlərin model üçün kifayət qədər çətin olduğundan əmin olun. Siqnal-küy nisbətini yaxşılaşdırmaq üçün qiymətləndirmələri iterasiya edin. Transkriptləri oxuyun!
AI agent qiymətləndirməsi hələ yeni yaranan, sürətlə inkişaf edən bir sahədir. Agentlər daha uzun tapşırıqlar götürdükcə, çox-agent sistemlərində əməkdaşlıq etdikcə və getdikcə daha subyektiv işləri idarə etdikcə, texnikalarımızı uyğunlaşdırmalı olacağıq. Daha çox öyrəndikcə ən yaxşı praktikalarımızı paylaşmağa davam edəcəyik.
Təşəkkürlər
Mikaela Grace, Jeremy Hadfield, Rodrigo Olivares və Jiri De Jonghe tərəfindən yazılmışdır. Həmçinin David Hershey, Gian Segato, Mike Merrill, Alex Shaw, Nicholas Carlini, Ethan Dixon, Pedram Navid, Jake Eaton, Alyssa Baum, Lina Tawfik, Karen Zhou, Alexander Bricken, Sam Kennedy, Robert Ying və digərlərinə töhfələrinə görə minnətdarıq. Qiymətləndirmələr üzərində əməkdaşlıq edərək öyrəndiyimiz müştərilərə və tərəfdaşlara, o cümlədən iGent, Cognition, Bolt, Sierra, Vals.ai, Macroscope, PromptLayer, Stripe, Shopify, Terminal Bench komandasına və digərlərinə xüsusi təşəkkür. Bu iş Anthropic-də qiymətləndirmə praktikasının inkişafına kömək edən bir neçə komandanın kollektiv səylərini əks etdirir.
Əlavə: Qiymətləndirmə çərçivələri
Bir neçə açıq mənbəli və kommersiya çərçivəsi komandalara sıfırdan infrastruktur qurmadan agent qiymətləndirmələrini həyata keçirməkdə kömək edə bilər. Düzgün seçim agent növünüzdən, mövcud texnoloji yığınınızdan və oflayn qiymətləndirməyə, istehsal müşahidəsinə və ya hər ikisinə ehtiyacınız olub-olmamasından asılıdır.
Harbor konteynerləşdirilmiş mühitlərdə agentləri işə salmaq üçün nəzərdə tutulub, bulud provayderləri arasında miqyasda sınaqlar aparmaq üçün infrastruktur və tapşırıqları və qiymətləndiricilərini müəyyənləşdirmək üçün standartlaşdırılmış format təqdim edir. Terminal-Bench 2.0 kimi populyar benchmarklar Harbor reyestri vasitəsilə paylanır ki, bu da mövcud benchmarkları xüsusi qiymətləndirmə paketləri ilə birlikdə asanlıqla icra etməyə imkan verir.
Promptfoo sətir uyğunlaşdırmasından LLM-hakim rubrikalarina qədər uzanan təsdiq növləri ilə sorğu testi üçün deklarativ YAML konfiqurasiyasına fokuslanmış yüngül, çevik və açıq mənbəli çərçivədir. Biz bir çox məhsul qiymətləndirmələrimiz üçün Promptfoo-nun bir versiyasını istifadə edirik.
Braintrust oflayn qiymətləndirməni istehsal müşahidəsi və eksperiment izləmə ilə birləşdirən platformadır — həm inkişaf zamanı iterasiya etmək, həm də istehsalda keyfiyyəti izləmək lazım olan komandalar üçün faydalıdır. Onun autoevals kitabxanası faktuallıq, relevanslıq və digər ümumi ölçülər üçün əvvəlcədən qurulmuş qiymətləndiricilər daxildir.
LangSmith LangChain ekosistemi ilə sıx inteqrasiya ilə izləmə, oflayn və onlayn qiymətləndirmələr və dataset idarəetməsi təklif edir. Langfuse verilənlərin yerləşdirilməsi tələbləri olan komandalar üçün öz-hostinqli açıq mənbəli alternativ olaraq oxşar imkanlar təqdim edir.
Bir çox komanda bir neçə aləti birləşdirir, öz qiymətləndirmə çərçivəsini yaradır və ya başlanğıc nöqtəsi olaraq sadə qiymətləndirmə skriptlərindən istifadə edir. Biz görürük ki, çərçivələr irəliləyişi sürətləndirmək və standartlaşdırmaq üçün dəyərli yol ola bilsə də, yalnız onlardan keçirdiyiniz qiymətləndirmə tapşırıqları qədər yaxşıdır. Çox vaxt iş axınınıza uyğun bir çərçivəni tez seçib, sonra enerjinizi yüksək keyfiyyətli test nümunələri və qiymətləndiricilərini iterasiya edərək qiymətləndirmələrin özünə yatırmaq daha yaxşıdır.