Claude indi veb, Google Workspace və istənilən inteqrasiya üzərindən axtarış apararaq mürəkkəb tapşırıqları yerinə yetirməyə imkan verən Tədqiqat imkanlarına malikdir.
Bu çox agentli sistemin prototipdan istehsala keçid yolu bizə sistem arxitekturası, alət dizaynı və prompt mühəndisliyi haqqında kritik dərslər öyrətdi. Çox agentli sistem birlikdə işləyən çoxsaylı agentlərdən (dövrədə müstəqil şəkildə alətlərdən istifadə edən LLM-lər) ibarətdir. Tədqiqat funksiyamız istifadəçi sorğuları əsasında tədqiqat prosesini planlaşdıran və sonra eyni vaxtda məlumat axtaran paralel agentlər yaratmaq üçün alətlərdən istifadə edən bir agenti əhatə edir. Çoxlu agentli sistemlər agent koordinasiyası, qiymətləndirmə və etibarlılıq sahəsində yeni çətinliklər yaradır.
Bu yazıda bizim üçün işə yarayan prinsipləri təhlil edirik — ümid edirik ki, öz çox agentli sistemlərinizi qurarkən onları faydalı tapacaqsınız.
Çox agentli sistemin üstünlükləri
Tədqiqat işi tələb olunan addımları əvvəlcədən proqnozlaşdırmanın çox çətin olduğu açıq uçlu problemləri əhatə edir. Mürəkkəb mövzuları araşdırmaq üçün sabit bir yol təyin etmək mümkün deyil, çünki proses mahiyyət etibarilə dinamik və yoldan asılıdır. İnsanlar tədqiqat aparanda kəşflər əsasında yanaşmalarını davamlı yeniləyir, araşdırma zamanı ortaya çıxan ipuçlarını izləyirlər.
Bu gözlənilməzlik süni intellekt agentlərini tədqiqat tapşırıqları üçün xüsusilə uyğun edir. Tədqiqat araşdırma gedişatında istiqaməti dəyişmək və ya əlaqəli bağlantıları araşdırmaq üçün çeviklik tələb edir. Model aralıq tapıntılar əsasında hansı istiqamətləri izləyəcəyi barədə qərarlar verərək çoxlu addımlar boyunca müstəqil işləməlidir. Xətti, birdəfəlik bir boru kəməri bu tapşırıqları həll edə bilməz.
Axtarışın mahiyyəti sıxlaşdırmadır: böyük həcmli məlumatdan anlayışlar çıxarmaq. Alt agentlər sualın müxtəlif aspektlərini eyni vaxtda araşdıraraq öz kontekst pəncərələrində paralel işləyərək sıxlaşdırmanı asanlaşdırır, sonra ən vacib tokenləri əsas tədqiqat agentinə ötürürlər. Hər alt agent həmçinin vəzifələrin ayrılmasını təmin edir — fərqli alətlər, promptlar və araşdırma trayektoriyaları — bu da yoldan asılılığı azaldır və hərtərəfli, müstəqil araşdırmalara imkan verir.
Zəka müəyyən bir həddə çatdıqda, çox agentli sistemlər performansı artırmağın həyati yoluna çevrilir. Məsələn, son 100,000 il ərzində fərdi insanlar daha ağıllı olsa da, insan cəmiyyətləri kollektiv zəka və koordinasiya qabiliyyəti sayəsində informasiya dövründə eksponensial şəkildə daha bacarıqlı olmuşdur. Hətta ümumi zəkaya malik agentlər belə fərdi olaraq fəaliyyət göstərəndə məhdudiyyətlərlə üzləşir; agent qrupları daha çox şey bacarır.
Daxili qiymətləndirmələrimiz göstərir ki, çox agentli tədqiqat sistemləri xüsusilə eyni vaxtda bir neçə müstəqil istiqaməti izləyən genişlik-əvvəl sorğularda üstündür. Biz müəyyən etdik ki, əsas agent kimi Claude Opus 4 və alt agentlər kimi Claude Sonnet 4 olan çox agentli sistem, daxili tədqiqat qiymətləndirməmizdə tək agentli Claude Opus 4-dən 90.2% daha yaxşı nəticə göstərdi. Məsələn, Information Technology S&P 500 şirkətlərinin bütün idarə heyəti üzvlərini müəyyən etmək tələb olunduqda, çox agentli sistem bunu alt agentlər üçün tapşırıqlara parçalayaraq düzgün cavabları tapdı, tək agent sistemi isə yavaş, ardıcıl axtarışlarla cavabı tapa bilmədi.
Çox agentli sistemlər əsasən problemi həll etmək üçün kifayət qədər token sərf etməyə kömək etdikləri üçün işləyir. Təhlilimizə görə, BrowseComp qiymətləndirməsində (brauzinq agentlərinin çətin tapılan məlumatları axtarma qabiliyyətini test edən) performans fərqinin 95%-ni üç amil izah edirdi. Token istifadəsinin özü fərqin 80%-ni izah edir, alət çağırışlarının sayı və model seçimi digər iki izahedici amildir. Bu tapıntı paralel düşünmə üçün əlavə tutum əlavə etmək məqsədilə işi ayrı kontekst pəncərələri olan agentlər arasında paylayan arxitekturamızı təsdiqləyir. Ən son Claude modelləri token istifadəsində böyük səmərəlilik artırıcıları kimi çıxış edir, çünki Claude Sonnet 4-ə keçid Claude Sonnet 3.7-nin token büdcəsini ikiqat artırmaqdan daha böyük performans artımıdır. Çox agentli arxitekturalar tək agentlərin imkanlarını aşan tapşırıqlar üçün token istifadəsini effektiv şəkildə miqyaslandırır.
Mənfi tərəfi də var: praktikada bu arxitekturalar tokenləri çox sürətlə sərf edir. Məlumatlarımıza görə, agentlər adətən söhbət qarşılıqlı əlaqələrindən təxminən 4 dəfə çox token istifadə edir, çox agentli sistemlər isə söhbətlərdən təxminən 15 dəfə çox token istifadə edir. İqtisadi cəhətdən sərfəli olması üçün çox agentli sistemlər tapşırığın dəyərinin artmış performans üçün ödəmə etmək üçün kifayət qədər yüksək olduğu tapşırıqlar tələb edir. Bundan əlavə, bütün agentlərin eyni konteksti paylaşmasını tələb edən və ya agentlər arasında çoxlu asılılıqlar olan bəzi sahələr hazırda çox agentli sistemlər üçün uyğun deyil. Məsələn, əksər proqramlaşdırma tapşırıqları tədqiqatdan daha az həqiqətən paralelləşdirilə bilən tapşırıqları əhatə edir və LLM agentləri hələ real vaxtda digər agentlərə koordinasiya etmək və tapşırıq həvalə etməkdə o qədər də yaxşı deyil. Biz müəyyən etdik ki, çox agentli sistemlər ağır paralelləşdirmə, tək kontekst pəncərələrini aşan məlumat və çoxsaylı mürəkkəb alətlərlə qarşılıqlı əlaqə tələb edən dəyərli tapşırıqlarda üstündür.
Research üçün arxitektura icmalı
Tədqiqat sistemimiz orkestrator-işçi nümunəsi ilə çox agentli arxitekturadan istifadə edir, burada əsas agent prosesi koordinasiya edir, paralel işləyən ixtisaslaşdırılmış alt agentlərə isə tapşırıqları həvalə edir.
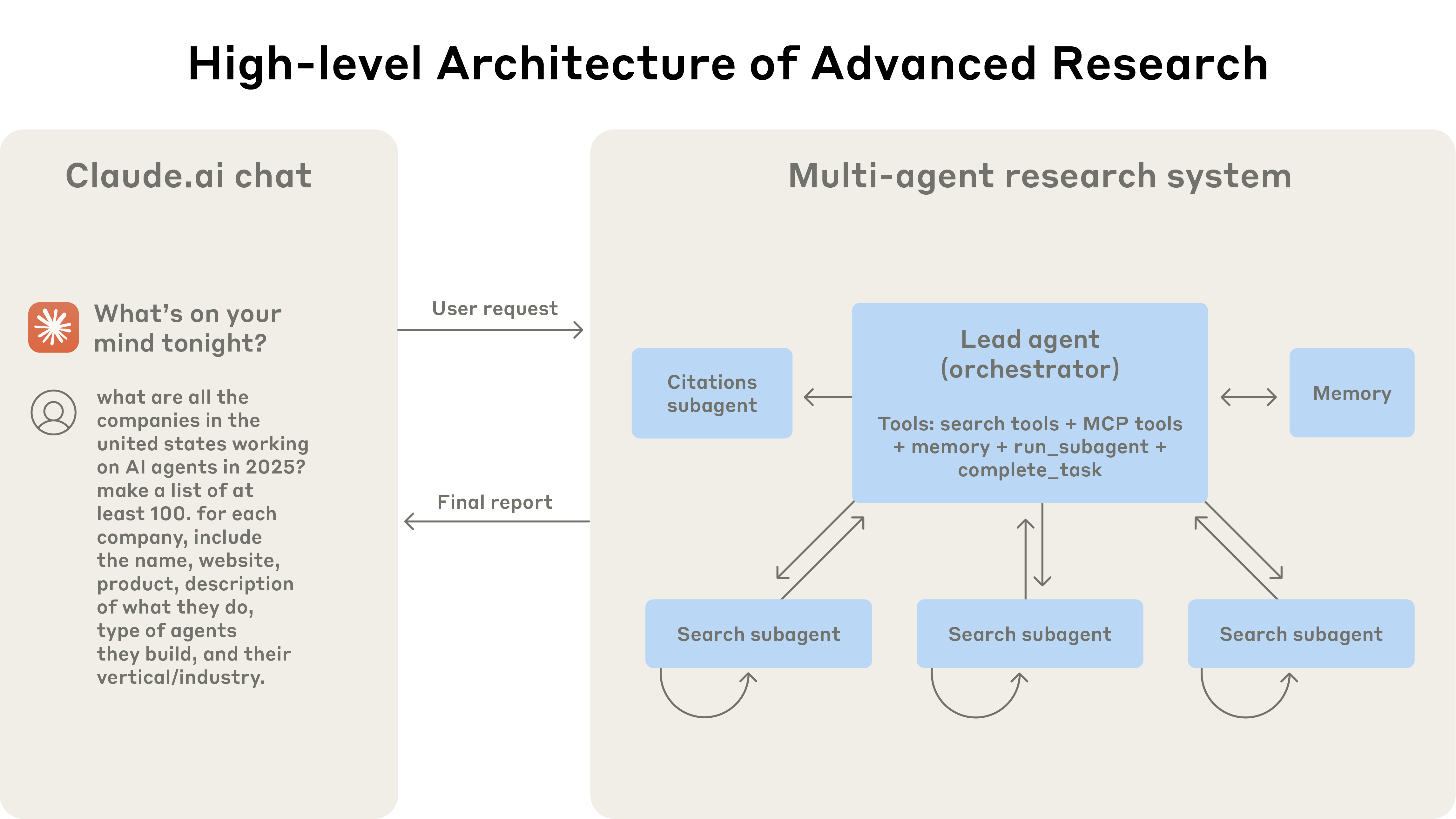 Fəaliyyətdə olan çox agentli arxitektura: istifadəçi sorğuları əsas agentdən keçir, o da müxtəlif aspektləri paralel şəkildə axtarmaq üçün ixtisaslaşdırılmış alt agentlər yaradır.
Fəaliyyətdə olan çox agentli arxitektura: istifadəçi sorğuları əsas agentdən keçir, o da müxtəlif aspektləri paralel şəkildə axtarmaq üçün ixtisaslaşdırılmış alt agentlər yaradır.
İstifadəçi sorğu göndərdikdə, əsas agent onu təhlil edir, strategiya hazırlayır və müxtəlif aspektləri eyni vaxtda araşdırmaq üçün alt agentlər yaradır. Yuxarıdakı diaqramda göstərildiyi kimi, alt agentlər məlumat toplamaq üçün axtarış alətlərindən iterativ şəkildə istifadə edərək ağıllı filtrlər rolunu oynayır — bu halda 2025-ci ildəki AI agent şirkətləri haqqında — və sonra yekun cavabı tərtib edə bilməsi üçün əsas agentə şirkətlər siyahısını qaytarır.
Retrieval Augmented Generation (RAG) istifadə edən ənənəvi yanaşmalar statik axtarışdan istifadə edir. Yəni, onlar giriş sorğusuna ən çox oxşar olan bəzi parçaları əldə edir və bu parçalardan cavab yaratmaq üçün istifadə edirlər. Bunun əksinə olaraq, bizim arxitekturamız dinamik şəkildə müvafiq məlumatı tapan, yeni tapıntılara uyğunlaşan və yüksək keyfiyyətli cavablar formalaşdırmaq üçün nəticələri təhlil edən çox addımlı axtarışdan istifadə edir.
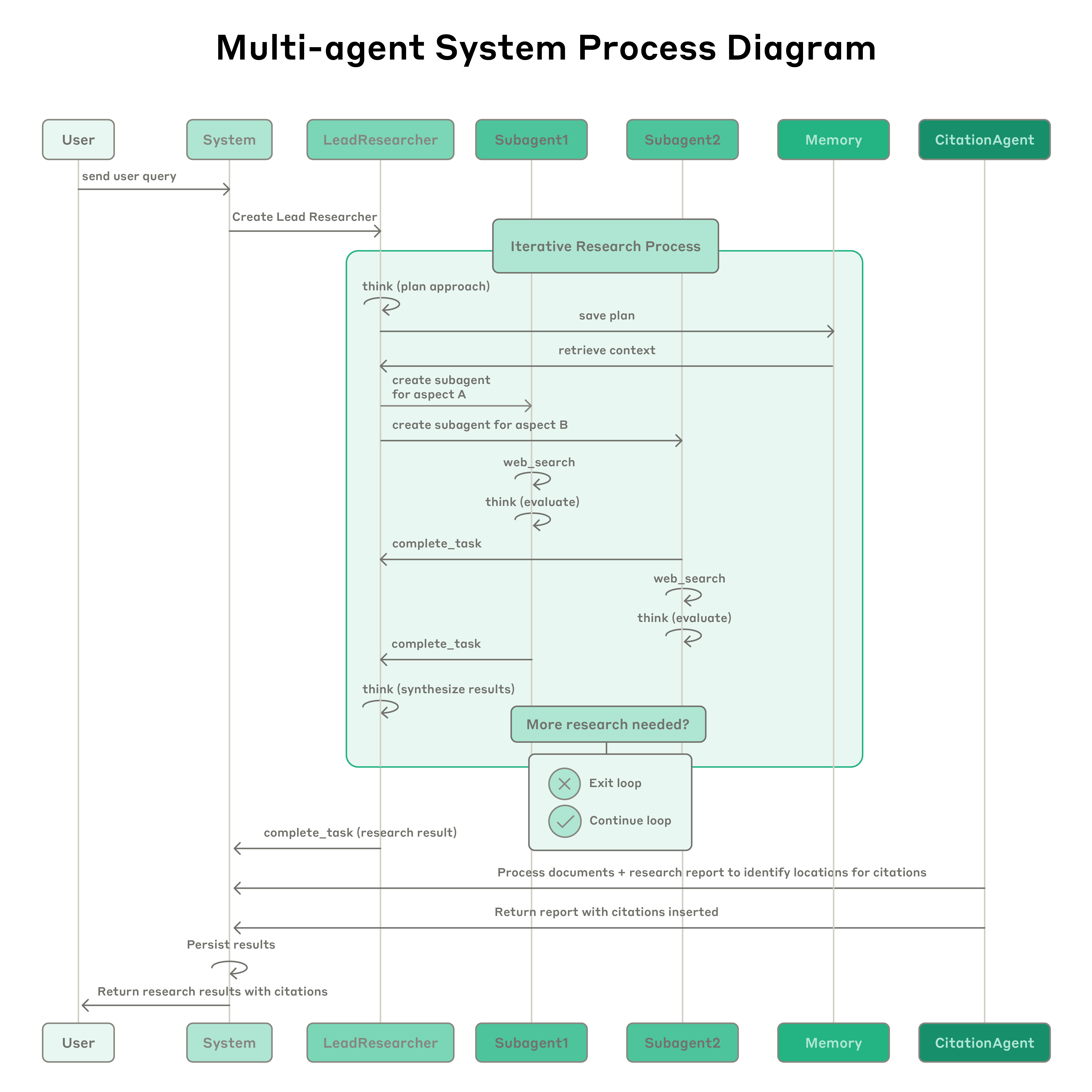 Çox agentli Tədqiqat sistemimizin tam iş prosesini göstərən proses diaqramı. İstifadəçi sorğu göndərdikdə, sistem iterativ tədqiqat prosesinə başlayan LeadResearcher agenti yaradır. LeadResearcher əvvəlcə yanaşma haqqında düşünür və konteksti saxlamaq üçün planını Memory-yə yazır, çünki kontekst pəncərəsi 200,000 tokeni keçdikdə kəsiləcək və planı saxlamaq vacibdir. Sonra konkret tədqiqat tapşırıqları ilə ixtisaslaşdırılmış alt agentlər yaradır (burada ikisi göstərilir, lakin istənilən sayda ola bilər). Hər alt agent müstəqil şəkildə veb axtarışları aparır, interleaved thinking istifadə edərək alət nəticələrini qiymətləndirir və tapıntılarını LeadResearcher-ə qaytarır. LeadResearcher bu nəticələri sintez edir və daha çox tədqiqatın lazım olub-olmadığına qərar verir — lazımdırsa, əlavə alt agentlər yarada və ya strategiyasını təkmilləşdirə bilər. Kifayət qədər məlumat toplandıqdan sonra sistem tədqiqat dövrəsindən çıxır və bütün tapıntıları sənədləri və tədqiqat hesabatını emal edərək istinadlar üçün konkret yerləri müəyyən edən CitationAgent-ə ötürür. Bu, bütün iddiaların mənbələrinə düzgün şəkildə istinad edilməsini təmin edir. Yekun tədqiqat nəticələri istinadlarla birlikdə istifadəçiyə qaytarılır.
Çox agentli Tədqiqat sistemimizin tam iş prosesini göstərən proses diaqramı. İstifadəçi sorğu göndərdikdə, sistem iterativ tədqiqat prosesinə başlayan LeadResearcher agenti yaradır. LeadResearcher əvvəlcə yanaşma haqqında düşünür və konteksti saxlamaq üçün planını Memory-yə yazır, çünki kontekst pəncərəsi 200,000 tokeni keçdikdə kəsiləcək və planı saxlamaq vacibdir. Sonra konkret tədqiqat tapşırıqları ilə ixtisaslaşdırılmış alt agentlər yaradır (burada ikisi göstərilir, lakin istənilən sayda ola bilər). Hər alt agent müstəqil şəkildə veb axtarışları aparır, interleaved thinking istifadə edərək alət nəticələrini qiymətləndirir və tapıntılarını LeadResearcher-ə qaytarır. LeadResearcher bu nəticələri sintez edir və daha çox tədqiqatın lazım olub-olmadığına qərar verir — lazımdırsa, əlavə alt agentlər yarada və ya strategiyasını təkmilləşdirə bilər. Kifayət qədər məlumat toplandıqdan sonra sistem tədqiqat dövrəsindən çıxır və bütün tapıntıları sənədləri və tədqiqat hesabatını emal edərək istinadlar üçün konkret yerləri müəyyən edən CitationAgent-ə ötürür. Bu, bütün iddiaların mənbələrinə düzgün şəkildə istinad edilməsini təmin edir. Yekun tədqiqat nəticələri istinadlarla birlikdə istifadəçiyə qaytarılır.
Tədqiqat agentləri üçün prompt mühəndisliyi və qiymətləndirmələr
Çox agentli sistemlərin tək agentli sistemlərdən əsas fərqləri var, o cümlədən koordinasiya mürəkkəbliyinin sürətli artması. Erkən agentlər sadə sorğular üçün 50 alt agent yaratmaq, mövcud olmayan mənbələr üçün vebdə sonsuz axtarış aparmaq və həddindən artıq yeniləmələrlə bir-birini yayındırmaq kimi səhvlər edirdilər. Hər agent prompt tərəfindən idarə olunduğu üçün, prompt mühəndisliyi bu davranışları yaxşılaşdırmaq üçün əsas vasitəmiz idi. Aşağıda agentlər üçün prompt yazma haqqında öyrəndiyimiz bəzi prinsiplər verilmişdir:
- Agentləriniz kimi düşünün. Promptları təkmilləşdirmək üçün onların təsirlərini başa düşməlisiniz. Bunu etməyə kömək etmək üçün biz sistemimizdəki dəqiq promptlar və alətlərlə Console istifadə edərək simulyasiyalar qurduq, sonra agentlərin addım-addım işini izlədik. Bu, uğursuzluq rejimlərini dərhal üzə çıxardı: agentlər artıq kifayət qədər nəticəyə malik olduqda davam etmək, həddindən artıq uzun axtarış sorğuları istifadə etmək və ya yanlış alətlər seçmək. Effektiv prompt yazma agentin dəqiq zehni modelini inkişaf etdirməyə əsaslanır ki, bu da ən təsirli dəyişiklikləri aydın edir.
- Orkestratorun necə tapşırıq həvalə edəcəyini öyrədin. Sistemimizin əsas agenti sorğuları alt tapşırıqlara parçalayır və onları alt agentlərə təsvir edir. Hər alt agentin məqsədə, çıxış formatına, istifadə ediləcək alətlər və mənbələr haqqında təlimata və aydın tapşırıq sərhədlərinə ehtiyacı var. Ətraflı tapşırıq təsvirləri olmadan agentlər işi təkrarlayır, boşluqlar buraxır və ya lazımi məlumatı tapa bilmir. Biz əvvəlcə əsas agentə "yarımkeçirici çatışmazlığını araşdırın" kimi sadə, qısa təlimatlar verməyə icazə verdik, lakin bu təlimatların çox vaxt kifayət qədər qeyri-müəyyən olduğunu gördük ki, alt agentlər tapşırığı yanlış şərh edir və ya digər agentlərlə eyni axtarışları aparırdılar. Məsələn, bir alt agent 2021-ci il avtomobil çip böhranını araşdırarkən, digər 2 nəfər effektiv iş bölgüsü olmadan cari 2025-ci il tədarük zəncirləri haqqında eyni işi təkrarlayırdı.
- Səyi sorğunun mürəkkəbliyinə uyğunlaşdırın. Agentlər müxtəlif tapşırıqlar üçün uyğun səy səviyyəsini müəyyən etməkdə çətinlik çəkir, ona görə biz miqyaslama qaydalarını promptlara daxil etdik. Sadə fakt tapma yalnız 3-10 alət çağırışı ilə 1 agent tələb edir, birbaşa müqayisələr hər biri 10-15 çağırış ilə 2-4 alt agent tələb edə bilər, mürəkkəb tədqiqat isə aydın şəkildə bölünmüş məsuliyyətlərlə 10-dan çox alt agent istifadə edə bilər. Bu açıq təlimatlar əsas agentə resursları effektiv şəkildə paylamağa kömək edir və erkən versiyalarımızda tez-tez rast gəlinən uğursuzluq rejimi olan sadə sorğulara həddindən artıq investisiya qoymağın qarşısını alır.
- Alət dizaynı və seçimi kritik əhəmiyyət daşıyır. Agent-alət interfeysləri insan-kompüter interfeysləri qədər kritikdir. Düzgün alətin istifadəsi effektivdir — çox vaxt bu mütləq zəruridir. Məsələn, yalnız Slack-da mövcud olan kontekst üçün vebdə axtarış aparan agent əvvəlcədən uğursuzluğa məhkumdur. Modelə xarici alətlərə giriş imkanı verən MCP serverləri ilə bu problem mürəkkəbləşir, çünki agentlər son dərəcə fərqli keyfiyyətdə təsvirləri olan əvvəllər görünməmiş alətlərlə qarşılaşır. Biz agentlərimizə açıq evristik qaydalar verdik: məsələn, əvvəlcə bütün mövcud alətları nəzərdən keçirin, alət istifadəsini istifadəçi niyyəti ilə uyğunlaşdırın, geniş xarici araşdırma üçün vebdə axtarın və ya ümumi alətlər əvəzinə ixtisaslaşdırılmış alətlərə üstünlük verin. Pis alət təsvirləri agentləri tamamilə yanlış istiqamətə yönəldə bilər, buna görə hər alətin fərqli məqsədi və aydın təsviri olmalıdır.
- Agentlərin özlərini təkmilləşdirməsinə icazə verin. Biz müəyyən etdik ki, Claude 4 modelləri əla prompt mühəndisləri ola bilər. Prompt və uğursuzluq rejimi verildikdə, onlar agentin niyə uğursuz olduğunu diaqnoz edə və təkmilləşdirmələr təklif edə bilirlər. Biz hətta alət test edən bir agent yaratdıq — qüsurlu MCP aləti verildikdə, o aləti istifadə etməyə çalışır və sonra uğursuzluqların qarşısını almaq üçün alət təsvirini yenidən yazır. Aləti onlarla dəfə test edərək, bu agent əsas nüansları və xətaları tapdı. Alət erqonomikasını təkmilləşdirmək üçün bu proses yeni təsvirdən istifadə edən gələcək agentlər üçün tapşırığı tamamlama vaxtında 40% azalma ilə nəticələndi, çünki onlar əksər səhvlərdən qaça bildilər.
- Geniş başlayın, sonra daraldın. Axtarış strategiyası peşəkar insan tədqiqatını əks etdirməlidir: xüsusi detallara keçməzdən əvvəl mənzərəni araşdırın. Agentlər adətən az nəticə qaytaran həddindən artıq uzun, konkret sorğulara meyl edirlər. Biz bu meylə qarşı agentləri qısa, geniş sorğularla başlamağa, mövcud olanı qiymətləndirməyə, sonra tədricən fokuslanmağa yönləndirərək müdaxilə etdik.
- Düşünmə prosesini istiqamətləndirin. Genişləndirilmiş düşünmə rejimi, Claude-un görünən düşünmə prosesində əlavə tokenlər çıxarmasına yol açır və idarə edilə bilən bir qaralama dəftəri kimi xidmət edə bilər. Əsas agent düşünmədən istifadə edərək yanaşmasını planlaşdırır, hansı alətlərin tapşırığa uyğun olduğunu qiymətləndirir, sorğu mürəkkəbliyini və alt agent sayını müəyyən edir, hər alt agentin rolunu təyin edir. Testlərimiz göstərdi ki, genişləndirilmiş düşünmə təlimatın izlənməsini, düşünmə qabiliyyətini və səmərəliliyi artırdı. Alt agentlər də planlaşdırır, sonra alət nəticələrindən sonra keyfiyyəti qiymətləndirmək, boşluqları müəyyən etmək və növbəti sorğunu dəqiqləşdirmək üçün interleaved thinking istifadə edir. Bu, alt agentləri istənilən tapşırığa uyğunlaşmaqda daha effektiv edir.
- Paralel alət çağırışları sürəti və performansı dəyişdirir. Mürəkkəb tədqiqat tapşırıqları təbii olaraq çoxlu mənbələrin araşdırılmasını əhatə edir. Erkən agentlərimiz ardıcıl axtarışlar aparırdı ki, bu da ağrılı dərəcədə yavaş idi. Sürət üçün biz iki növ paralelləşdirmə tətbiq etdik: (1) əsas agent ardıcıl deyil, paralel şəkildə 3-5 alt agent işə salır; (2) alt agentlər 3+ aləti paralel istifadə edir. Bu dəyişikliklər mürəkkəb sorğular üçün tədqiqat müddətini 90%-ə qədər azaltdı və Research-ün saatlar əvəzinə dəqiqələr ərzində digər sistemlərdən daha çox məlumatı əhatə edərək daha çox iş görməsinə imkan verdi.
Bizim prompt strategiyamız sərt qaydalar əvəzinə yaxşı evristik qaydalar aşılamağa yönəlib. Bacarıqlı insanların tədqiqat tapşırıqlarına necə yanaşdığını öyrəndik və bu strategiyaları promptlarımızda kodlaşdırdıq — çətin sualları daha kiçik tapşırıqlara bölmək, mənbələrin keyfiyyətini diqqətlə qiymətləndirmək, yeni məlumatlara əsasən axtarış yanaşmalarını tənzimləmək və dərinliyə (bir mövzunu ətraflı araşdırmaq) qarşı genişliyə (çoxlu mövzuları paralel araşdırmaq) nə vaxt diqqət yetirməyi bilmək kimi strategiyalar. Biz həmçinin agentlərin nəzarətdən çıxmasının qarşısını almaq üçün açıq mühafizə qaydaları qoyaraq gözlənilməz yan təsirləri proaktiv şəkildə azaltdıq. Nəhayət, müşahidə qabiliyyəti və test nümunələri ilə sürətli iterasiya dövrünə diqqət yetirdik.
Agentlərin effektiv qiymətləndirilməsi
Yaxşı qiymətləndirmələr etibarlı AI tətbiqləri qurmaq üçün vacibdir və agentlər də fərqli deyil. Lakin çox agentli sistemlərin qiymətləndirilməsi özünəməxsus çətinliklər təqdim edir. Ənənəvi qiymətləndirmələr adətən AI-ın hər dəfə eyni addımları izlədiyini güman edir: X girişi verildikdə, sistem Z çıxışını əldə etmək üçün Y yolunu izləməlidir. Lakin çox agentli sistemlər bu cür işləmir. Eyni başlanğıc nöqtəsi ilə belə, agentlər məqsədlərinə çatmaq üçün tamamilə fərqli, lakin etibarlı yollar tuta bilər. Bir agent üç mənbəni axtara bilər, digəri isə onu, və ya eyni cavabı tapmaq üçün fərqli alətlərdən istifadə edə bilərlər. Düzgün addımların nə olduğunu həmişə bilmədiyimiz üçün, adətən agentlərin əvvəlcədən təyin etdiyimiz "düzgün" addımları izləyib-izləmədiyini yoxlaya bilmirik. Bunun əvəzinə, agentlərin ağlabatan proses izləyərək düzgün nəticələrə çatıb-çatmadığını mühakimə edən çevik qiymətləndirmə üsullarına ehtiyacımız var.
Kiçik nümunələrlə dərhal qiymətləndirməyə başlayın. Erkən agent inkişafında dəyişikliklər dramatik təsir göstərir, çünki asan həll edilən problemlər çoxdur. Bir prompt düzəlişi uğur nisbətlərini 30%-dən 80%-ə artıra bilər. Bu qədər böyük təsir ölçüləri ilə dəyişiklikləri yalnız bir neçə test nümunəsi ilə görə bilərsiniz. Biz real istifadə nümunələrini təmsil edən təxminən 20 sorğu dəsti ilə başladıq. Bu sorğuları test etmək çox vaxt dəyişikliklərin təsirini aydın şəkildə görməyə imkan verirdi. Biz tez-tez eşidirik ki, AI developer komandaları yalnız yüzlərlə test nümunəsi olan böyük qiymətləndirmələrin faydalı olduğuna inandıqları üçün qiymətləndirmə yaratmağı gecikdirirlər. Lakin daha hərtərəfli qiymətləndirmələr qura bilənə qədər gözləmək əvəzinə, dərhal bir neçə nümunə ilə kiçik miqyaslı testə başlamaq daha yaxşıdır.
LLM-hakim-kimi qiymətləndirmə düzgün aparıldıqda miqyaslanır. Tədqiqat çıxışlarını proqrammatik olaraq qiymətləndirmək çətindir, çünki onlar sərbəst formatlı mətndir və nadir hallarda tək bir düzgün cavabı olur. LLM-lər çıxışları qiymətləndirmək üçün təbii uyğundur. Biz hər çıxışı rubrikadakı meyarlara qarşı qiymətləndirən LLM hakimi istifadə etdik: faktiki dəqiqlik (iddialar mənbələrlə uyğun gəlirmi?), istinad dəqiqliyi (istinad edilən mənbələr iddialarla uyğun gəlirmi?), tamlıq (bütün tələb olunan aspektlər əhatə olunubmu?), mənbə keyfiyyəti (aşağı keyfiyyətli ikinci dərəcəli mənbələr əvəzinə birinci dərəcəli mənbələrdən istifadə edilibmi?) və alət səmərəliliyi (düzgün alətlərdən ağlabatan sayda istifadə edilibmi?). Hər komponenti qiymətləndirmək üçün çoxlu hakimlərlə sınaq keçirdik, lakin 0.0-1.0 balları və keçdi-kəsildi dərəcəsi çıxaran tək prompt ilə tək LLM çağırışının ən ardıcıl olduğunu və insan mühakimələri ilə ən çox uyğunlaşdığını gördük. Bu üsul xüsusilə qiymətləndirmə test nümunələrinin aydın cavabı olduqda effektiv idi və biz LLM hakimini sadəcə cavabın düzgün olub-olmadığını yoxlamaq üçün istifadə edə bilərdik (yəni, ən böyük 3 AR-GE büdcəsinə malik əczaçılıq şirkətlərini düzgün sadaladımı?). LLM-nin hakim kimi istifadəsi yüzlərlə çıxışı miqyaslana bilən şəkildə qiymətləndirməyə imkan verdi.
İnsan qiymətləndirməsi avtomatlaşdırmanın qaçırdığını tutur. Agentləri test edən insanlar qiymətləndirmələrin qaçırdığı uç halları tapır. Bunlara qeyri-adi sorğularda hallüsinasiya edilmiş cavablar, sistem uğursuzluqları və ya incə mənbə seçimi qərəzlilikləri daxildir. Bizim halda, insan test ediciləri erkən agentlərimizin akademik PDF-lər və ya şəxsi bloqlar kimi daha etibarlı, lakin aşağı sıralanmış mənbələr əvəzinə ardıcıl olaraq SEO-optimizasiya olunmuş kontent fermalarını seçdiyini aşkar etdilər. Promptlarımıza mənbə keyfiyyəti evristik qaydaları əlavə etmək bu problemi həll etməyə kömək etdi. Avtomatlaşdırılmış qiymətləndirmələr dünyasında belə, əl ilə test etmə vacib olaraq qalır.
Başlıq: Çoxagentli tədqiqat sistemimizi necə qurduq (2-ci hissə)
Məzmun:
Çoxagentli sistemlərdə xüsusi proqramlaşdırma olmadan yaranan emerqent davranışlar mövcuddur. Məsələn, aparıcı agentdə kiçik dəyişikliklər alt agentlərin davranışını gözlənilməz şəkildə dəyişdirə bilər. Uğur yalnız fərdi agent davranışını deyil, qarşılıqlı əlaqə nümunələrini anlamağı tələb edir. Buna görə də bu agentlər üçün ən yaxşı promptlar sadəcə sərt təlimatlar deyil, əmək bölgüsünü, problem həlli yanaşmalarını və səy büdcələrini müəyyən edən əməkdaşlıq çərçivələridir. Bunu düzgün etmək diqqətli prompt və alət dizaynına, möhkəm evristikalara, müşahidə qabiliyyətinə və sıx əks əlaqə dövrlərinə əsaslanır. Sistemimizdən nümunə promptlar üçün Cookbook-dakı açıq mənbəli promptlara baxın.
İstehsal etibarlılığı və mühəndislik çətinlikləri
Ənənəvi proqram təminatında bir xəta funksionallığı poza, performansı azalda və ya kəsintilərə səbəb ola bilər. Agentli sistemlərdə isə kiçik dəyişikliklər böyük davranış dəyişikliklərinə kaskad şəklində keçir ki, bu da uzunmüddətli prosesdə vəziyyəti saxlamalı olan mürəkkəb agentlər üçün kod yazmağı olduqca çətinləşdirir.
Agentlər vəziyyətlidir və xətalar yığılır. Agentlər uzun müddət işləyə bilər və bir çox alət çağırışı boyunca vəziyyəti saxlaya bilər. Bu o deməkdir ki, biz kodu davamlı şəkildə icra etməli və yol boyu xətaları idarə etməliyik. Effektiv tədbir görülmədən kiçik sistem nasazlıqları agentlər üçün fəlakətli ola bilər. Xətalar baş verdikdə, sadəcə başdan başlaya bilmərik: yenidən başlatmalar bahalıdır və istifadəçilər üçün əsəbləşdiricidir. Bunun əvəzinə, agentin xətalar baş verdiyi yerdən davam edə biləcəyi sistemlər qurduq. Həmçinin problemləri zərif şəkildə həll etmək üçün modelin zəkasından istifadə edirik: məsələn, alətin uğursuz olduğunu agentə bildirmək və onun uyğunlaşmasına imkan vermək təəccüblü dərəcədə yaxşı işləyir. Biz Claude üzərində qurulmuş AI agentlərinin adaptivliyini yenidən cəhd məntiqi və müntəzəm yoxlama nöqtələri kimi deterministik qoruma tədbirləri ilə birləşdiririk.
Debaqlanma yeni yanaşmalardan faydalanır. Agentlər dinamik qərarlar verir və eyni promptlarla belə çalışmalar arasında qeyri-deterministikdir. Bu, debaqlanmanı çətinləşdirir. Məsələn, istifadəçilər agentlərin "aşkar məlumatı tapmadığını" bildirirdilər, lakin biz səbəbini görə bilmirdik. Agentlər pis axtarış sorğuları istifadə edirdilər? Zəif mənbələr seçirdilər? Alət nasazlıqlarına rast gəlirdilər? Tam istehsal izləməsi əlavə etmək bizə agentlərin niyə uğursuz olduğunu diaqnoz etməyə və problemləri sistematik şəkildə həll etməyə imkan verdi. Standart müşahidə qabiliyyətindən əlavə, biz istifadəçi məxfiliyini qorumaq üçün fərdi söhbətlərin məzmununu izləmədən agent qərar nümunələrini və qarşılıqlı əlaqə strukturlarını izləyirik. Bu yüksək səviyyəli müşahidə qabiliyyəti bizə kök səbəbləri diaqnoz etməyə, gözlənilməz davranışları kəşf etməyə və ümumi nasazlıqları aradan qaldırmağa kömək etdi.
Yerləşdirmə diqqətli koordinasiya tələb edir. Agent sistemləri demək olar ki, fasiləsiz işləyən promptlar, alətlər və icra məntiqinin yüksək vəziyyətli şəbəkələridir. Bu o deməkdir ki, biz yeniləmələri yerləşdirəndə agentlər prosesinin istənilən yerində ola bilərlər. Buna görə də yaxşı niyyətli kod dəyişikliklərimizin mövcud agentləri pozmasının qarşısını almalıyıq. Hər agenti eyni anda yeni versiyaya yeniləyə bilmərik. Bunun əvəzinə, işləyən agentləri pozmamaq üçün rainbow yerləşdirmələrindən istifadə edirik — hər iki versiyanı eyni anda işlək saxlayaraq trafiki köhnədən yeniyə tədricən yönləndiririk.
Sinxron icra darboğazlar yaradır. Hal-hazırda aparıcı agentlərimiz alt agentləri sinxron şəkildə icra edir, davam etməzdən əvvəl hər alt agent dəstinin tamamlanmasını gözləyir. Bu, koordinasiyanı sadələşdirir, lakin agentlər arasında məlumat axınında darboğazlar yaradır. Məsələn, aparıcı agent alt agentləri istiqamətləndirə bilmir, alt agentlər bir-biri ilə koordinasiya edə bilmir və tək bir alt agentin axtarışını bitirməsini gözləyərkən bütün sistem bloklanmış ola bilər. Asinxron icra əlavə paralellik təmin edəcək: agentlər eyni vaxtda işləyib ehtiyac olduqda yeni alt agentlər yaradacaq. Lakin bu asinxronluq nəticələrin koordinasiyası, vəziyyət ardıcıllığı və alt agentlər arasında xəta yayılması sahəsində çətinliklər əlavə edir. Modellər daha uzun və daha mürəkkəb tədqiqat tapşırıqlarını idarə edə bildikcə, performans qazanclarının mürəkkəbliyi haqq-hesab edəcəyini gözləyirik.
Nəticə
AI agentləri qurarkən son mil çox vaxt səyahətin böyük hissəsinə çevrilir. Tərtibatçı maşınlarında işləyən kod bazaları etibarlı istehsal sistemlərinə çevrilmək üçün əhəmiyyətli mühəndislik tələb edir. Agentli sistemlərdə xətaların yığılma xarakteri o deməkdir ki, ənənəvi proqram təminatı üçün kiçik problemlər agentləri tamamilə yolundan çıxara bilər. Bir addımın uğursuz olması agentlərin tamamilə fərqli trayektoriyaları araşdırmasına səbəb ola bilər ki, bu da gözlənilməz nəticələrə gətirib çıxarır. Bu yazıda təsvir edilən bütün səbəblərə görə, prototip və istehsal arasındakı boşluq çox vaxt gözləniləndən daha genişdir.
Bu çətinliklərə baxmayaraq, çoxagentli sistemlər açıq tədqiqat tapşırıqları üçün dəyərli olduğunu sübut etdi. İstifadəçilər bildirdilər ki, Claude onlara nəzərdən keçirmədikləri biznes imkanlarını tapmağa, mürəkkəb səhiyyə seçimlərində naviqasiya etməyə, çətin texniki xətaları həll etməyə və təkbaşına tapa bilməyəcəkləri tədqiqat əlaqələrini üzə çıxararaq günlərlə iş qənaət etməyə kömək etdi. Çoxagentli tədqiqat sistemləri diqqətli mühəndislik, hərtərəfli test, detallara diqqətli prompt və alət dizaynı, möhkəm əməliyyat təcrübələri və cari agent imkanlarını dərindən anlayan tədqiqat, məhsul və mühəndislik komandaları arasında sıx əməkdaşlıqla miqyasda etibarlı şəkildə işləyə bilər. Biz artıq bu sistemlərin insanların mürəkkəb problemləri necə həll etdiyini dəyişdirdiyini görürük.
 İnsanların bu gün Research xüsusiyyətini ən çox necə istifadə etdiyini göstərən Clio embedding qrafiki. Ən populyar istifadə kateqoriyaları: ixtisaslaşdırılmış sahələr üzrə proqram təminatı sistemlərinin inkişaf etdirilməsi (10%), peşəkar və texniki məzmunun hazırlanması və optimallaşdırılması (8%), biznes artımı və gəlir əldə etmə strategiyalarının hazırlanması (8%), akademik tədqiqat və tədris materiallarının hazırlanmasına kömək (7%), və insanlar, yerlər və ya təşkilatlar haqqında məlumatların araşdırılması və yoxlanılması (5%).
İnsanların bu gün Research xüsusiyyətini ən çox necə istifadə etdiyini göstərən Clio embedding qrafiki. Ən populyar istifadə kateqoriyaları: ixtisaslaşdırılmış sahələr üzrə proqram təminatı sistemlərinin inkişaf etdirilməsi (10%), peşəkar və texniki məzmunun hazırlanması və optimallaşdırılması (8%), biznes artımı və gəlir əldə etmə strategiyalarının hazırlanması (8%), akademik tədqiqat və tədris materiallarının hazırlanmasına kömək (7%), və insanlar, yerlər və ya təşkilatlar haqqında məlumatların araşdırılması və yoxlanılması (5%).
Təşəkkürlər
Jeremy Hadfield, Barry Zhang, Kenneth Lien, Florian Scholz, Jeremy Fox və Daniel Ford tərəfindən yazılmışdır. Bu iş Research xüsusiyyətini mümkün edən Anthropic-dəki bir neçə komandanın kollektiv səylərini əks etdirir. Bu mürəkkəb çoxagentli sistemi istehsala çıxaran Anthropic tətbiqlər mühəndislik komandasına xüsusi təşəkkürlər. Həmçinin əla rəylərinə görə erkən istifadəçilərimizə minnətdarıq.
Əlavə
Aşağıda çoxagentli sistemlər üçün bəzi əlavə müxtəlif məsləhətlər verilmişdir.
Bir çox addım boyunca vəziyyəti dəyişdirən agentlərin son vəziyyət qiymətləndirməsi. Çox addımlı söhbətlər boyunca davamlı vəziyyəti dəyişdirən agentlərin qiymətləndirilməsi unikal çətinliklər təqdim edir. Yalnız oxuyan tədqiqat tapşırıqlarından fərqli olaraq, hər bir fəaliyyət sonrakı addımlar üçün mühiti dəyişdirə bilər ki, bu da ənənəvi qiymətləndirmə metodlarının idarə etməkdə çətinlik çəkdiyi asılılıqlar yaradır. Biz addım-addım təhlidən çox son vəziyyət qiymətləndirməsinə diqqət yetirərək uğur əldə etdik. Agentin müəyyən bir prosesə əməl edib-etmədiyini mühakimə etmək əvəzinə, düzgün son vəziyyətə çatıb-çatmadığını qiymətləndirin. Bu yanaşma agentlərin nəzərdə tutulan nəticəni təmin etməyə davam edərkən eyni məqsədə alternativ yollar tapa biləcəyini etiraf edir. Mürəkkəb iş axınları üçün hər bir aralıq addımı yoxlamağa çalışmaq əvəzinə, müəyyən vəziyyət dəyişikliklərinin baş verməli olduğu diskret yoxlama nöqtələrinə qiymətləndirməni bölün.
Uzunmüddətli söhbət idarəetməsi. İstehsal agentləri tez-tez yüzlərlə addım əhatə edən söhbətlər aparır ki, bu da diqqətli kontekst idarəetmə strategiyaları tələb edir. Söhbətlər uzandıqca standart kontekst pəncərələri kifayət etmir və ağıllı sıxışdırma və yaddaş mexanizmləri lazım olur. Biz agentlərin yeni tapşırıqlara keçməzdən əvvəl tamamlanmış iş mərhələlərini ümumiləşdirdiyi və əsas məlumatı xarici yaddaşda saxladığı nümunələr tətbiq etdik. Kontekst limitləri yaxınlaşdıqda agentlər diqqətli təhvil-təslim vasitəsilə davamlılığı qoruyaraq təmiz kontekstlərlə yeni alt agentlər yarada bilər. Bundan əlavə, kontekst limitinə çatdıqda əvvəlki işi itirmək əvəzinə tədqiqat planı kimi saxlanmış konteksti yaddaşlarından əldə edə bilərlər. Bu paylanmış yanaşma uzun qarşılıqlı əlaqələr boyunca söhbət ardıcıllığını qoruyaraq kontekst daşmasının qarşısını alır.
"Telefon oyunu"nu minimuma endirmək üçün alt agentin fayl sisteminə çıxışı. Müəyyən nəticə növləri üçün birbaşa alt agent çıxışları əsas koordinatoru yan keçə bilər ki, bu da həm dəqiqliyi, həm də performansı yaxşılaşdırır. Alt agentlərin hər şeyi aparıcı agent vasitəsilə ötürməsini tələb etmək əvəzinə, ixtisaslaşdırılmış agentlərin müstəqil şəkildə davam edən çıxışlar yarada biləcəyi artefakt sistemləri tətbiq edin. Alt agentlər işlərini xarici sistemlərdə saxlamaq üçün alətlər çağırır, sonra koordinatora yüngül istinadlar qaytarır. Bu, çoxmərhələli emal zamanı məlumat itkisinin qarşısını alır və böyük çıxışların söhbət tarixçəsi vasitəsilə kopyalanmasından yaranan token xərclərini azaldır. Bu nümunə xüsusilə kod, hesabatlar və ya verilənlərin vizuallaşdırılması kimi strukturlaşdırılmış çıxışlar üçün yaxşı işləyir — burada alt agentin ixtisaslaşdırılmış promptu ümumi koordinatordan süzülməkdən daha yaxşı nəticələr verir.