Model Context Protocol (MCP) LLM agentlərini real dünya tapşırıqlarını həll etmək üçün potensial olaraq yüzlərlə alətlə gücləndirə bilər. Bəs bu alətləri maksimum effektiv necə edə bilərik?
Bu yazıda müxtəlif agent əsaslı süni intellekt sistemlərində performansı artırmaq üçün ən effektiv texnikalarımızı təsvir edirik1.
Əvvəlcə aşağıdakıları necə edə biləcəyinizi izah edirik:
- Alətlərinizin prototiplərini qurmaq və sınaqdan keçirmək
- Agentlərlə alətlərinizin hərtərəfli qiymətləndirmələrini yaratmaq və icra etmək
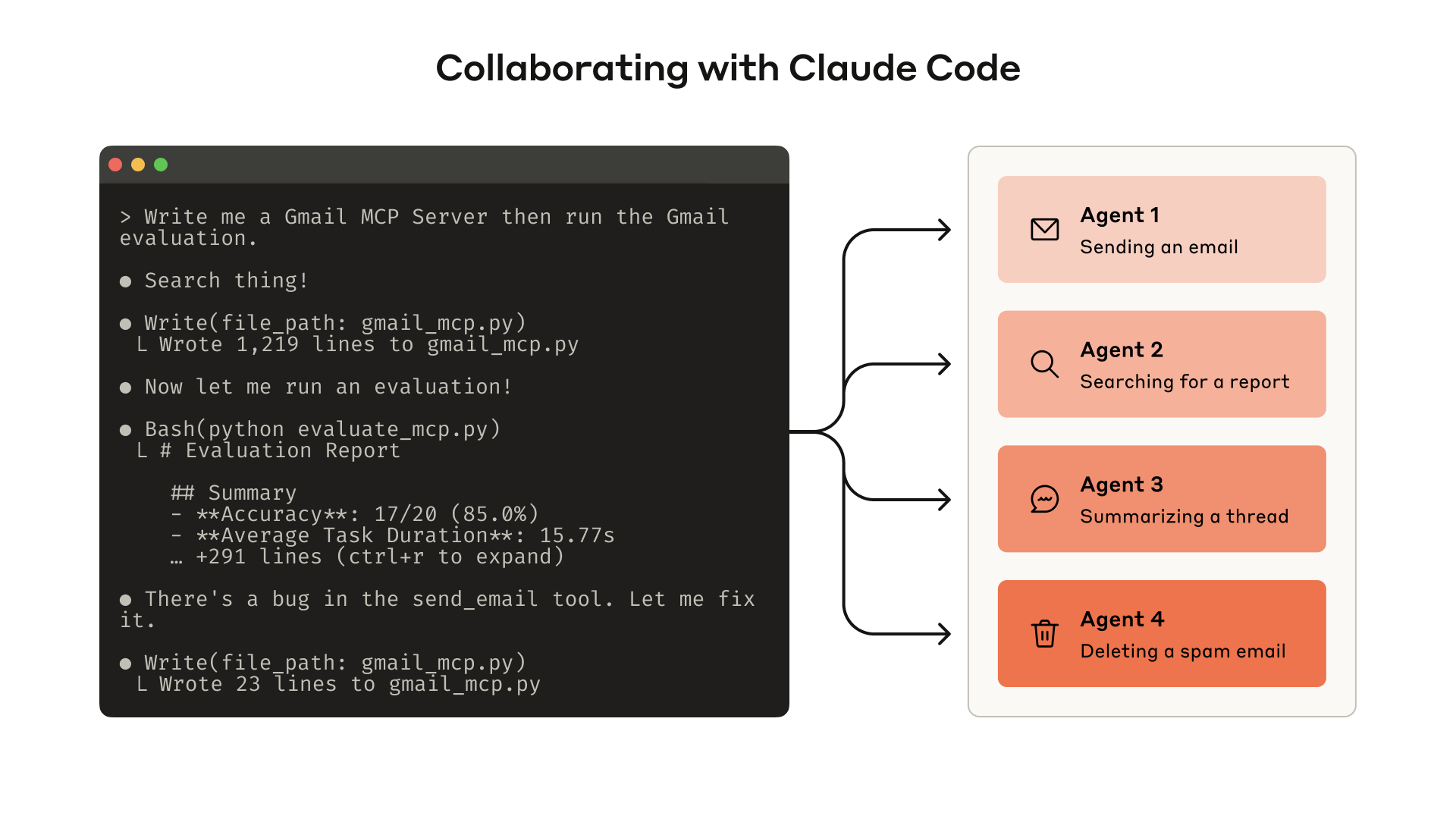
- Claude Code kimi agentlərlə əməkdaşlıq edərək alətlərinizin performansını avtomatik artırmaq
Sonda yol boyu müəyyən etdiyimiz yüksək keyfiyyətli alətlər yazmaq üçün əsas prinsiplərlə yekunlaşdırırıq:
- Tətbiq ediləcək (və edilməyəcək) düzgün alətləri seçmək
- Funksionallıqda aydın sərhədlər müəyyən etmək üçün alətləri ad fəzası ilə qruplaşdırmaq
- Alətlərdən agentlərə mənalı kontekst qaytarmaq
- Alət cavablarını token effektivliyi üçün optimallaşdırmaq
- Alət təsvirləri və spesifikasiyaları üçün prompt mühəndisliyi
 Qiymətləndirmə qurmaq alətlərinizin performansını sistematik şəkildə ölçməyə imkan verir. Claude Code-dan istifadə edərək alətlərinizi bu qiymətləndirməyə qarşı avtomatik optimallaşdıra bilərsiniz.
Qiymətləndirmə qurmaq alətlərinizin performansını sistematik şəkildə ölçməyə imkan verir. Claude Code-dan istifadə edərək alətlərinizi bu qiymətləndirməyə qarşı avtomatik optimallaşdıra bilərsiniz.
Alət nədir?
Hesablamada deterministik sistemlər eyni giriş verilən zaman hər dəfə eyni nəticəni istehsal edir, qeyri-deterministik sistemlər isə — agentlər kimi — eyni başlanğıc şərtlərində belə müxtəlif cavablar yarada bilər.
Ənənəvi olaraq proqram təminatı yazanda deterministik sistemlər arasında müqavilə qururuq. Məsələn, getWeather("NYC") funksiya çağırışı hər dəfə çağırıldığında tamamilə eyni şəkildə New York şəhərinin hava proqnozunu gətirəcək.
Alətlər deterministik sistemlər və qeyri-deterministik agentlər arasındakı müqaviləni əks etdirən yeni növ proqram təminatıdır. İstifadəçi "Bu gün çətir götürməliyəm?" deyə soruşduqda, agent hava aləti çağıra, ümumi biliklərindən cavab verə, və ya hətta əvvəlcə məkan haqqında aydınlaşdırıcı sual verə bilər. Bəzən agent hallüsinasiya edə və ya hətta aləti necə istifadə edəcəyini başa düşməyə bilər.
Bu o deməkdir ki, agentlər üçün proqram təminatı yazarkən yanaşmamızı kökündən yenidən düşünməliyik: alətləri və MCP serverlərini digər tərtibatçılar və ya sistemlər üçün funksiyalar və API-lər yazdığımız kimi yazmaq əvəzinə, onları agentlər üçün dizayn etməliyik.
Məqsədimiz agentlərin müxtəlif uğurlu strategiyalar izləmək üçün alətlərdən istifadə edərək geniş çeşidli tapşırıqları effektiv həll edə biləcəyi sahəni genişləndirməkdir. Xoşbəxtlikdən, təcrübəmizə əsasən, agentlər üçün ən "erqonomik" olan alətlər insanlar üçün də təəccüblü dərəcədə intuitiv olur.
Alətləri necə yazmaq olar
Bu bölmədə agentlərə verdiyiniz alətləri həm yazmaq, həm də təkmilləşdirmək üçün agentlərlə necə əməkdaşlıq edə biləcəyinizi təsvir edirik. Alətlərinizin sürətli prototipini qurmaqla və onları lokal sınaqdan keçirməklə başlayın. Sonra sonrakı dəyişiklikləri ölçmək üçün hərtərəfli qiymətləndirmə aparın. Agentlərlə birlikdə işləyərək, agentləriniz real dünya tapşırıqlarında güclü performans göstərənə qədər qiymətləndirmə və təkmilləşdirmə prosesini təkrarlaya bilərsiniz.
Prototip qurmaq
Əl ilə sınaqdan keçirmədən agentlərin hansı alətləri erqonomik tapacağını və hansını tapmayacağını əvvəlcədən proqnozlaşdırmaq çətin ola bilər. Alətlərinizin sürətli prototipini qurmaqla başlayın. Alətlərinizi yazmaq üçün Claude Code istifadə edirsinizsə (potensial olaraq bir dəfəlik), alətlərinizin asılı olacağı proqram kitabxanaları, API-lər və ya SDK-lar (potensial olaraq MCP SDK daxil olmaqla) üçün Claude-a sənədləşdirmə vermək faydalıdır. LLM-dostu sənədləşdirmə adətən rəsmi sənədləşdirmə saytlarında düz llms.txt fayllarında tapıla bilər (bizim API-nin nümunəsi burada).
Alətlərinizi lokal MCP serverinə və ya Desktop genişlənməsinə (DXT) bükməklə onları Claude Code və ya Claude Desktop tətbiqində qoşub sınaqdan keçirə bilərsiniz.
Lokal MCP serverinizi Claude Code-a qoşmaq üçün claude mcp add <name> <command> [args...] əmrini icra edin.
Lokal MCP serverinizi və ya DXT-ni Claude Desktop tətbiqinə qoşmaq üçün müvafiq olaraq Settings > Developer və ya Settings > Extensions bölməsinə keçin.
Alətlər həmçinin proqramatik sınaq üçün birbaşa Anthropic API çağırışlarına ötürülə bilər.
Hər hansı kəskin kənarları müəyyən etmək üçün alətləri özünüz sınayın. Alətlərinizin dəstəkləməsini gözlədiyiniz istifadə halları və prompt-lar haqqında intuisiya qurmaq üçün istifadəçilərinizdən rəy toplayın.
Qiymətləndirmə aparmaq
Sonra, Claude-un alətlərinizi nə dərəcədə yaxşı istifadə etdiyini qiymətləndirmə apararaq ölçməlisiniz. Real dünya istifadələrinə əsaslanan çoxlu qiymətləndirmə tapşırıqları yaratmaqla başlayın. Nəticələrinizi təhlil etmək və alətlərinizi necə təkmilləşdirəcəyinizi müəyyən etmək üçün agentlə əməkdaşlıq etməyi tövsiyə edirik. Bu prosesi başdan sona alət qiymətləndirmə kitabçamızda görə bilərsiniz.
 Daxili Slack alətlərimizin ayrılmış test dəsti performansı
Daxili Slack alətlərimizin ayrılmış test dəsti performansı
Qiymətləndirmə tapşırıqlarının yaradılması
İlkin prototipinizlə Claude Code alətlərinizi tez araşdıra və onlarla prompt-cavab cütləri yarada bilər. Prompt-lar real dünya istifadələrindən ilhamlanmalı və real məlumat mənbələri və xidmətlərinə (məsələn, daxili bilik bazaları və mikroservislər) əsaslanmalıdır. Alətlərinizi kifayət qədər mürəkkəbliklə stress-testdən keçirməyən həddən artıq sadə və ya səthi "sandbox" mühitlərindən qaçınmağınızı tövsiyə edirik. Güclü qiymətləndirmə tapşırıqları çoxsaylı alət çağırışları — potensial olaraq onlarla — tələb edə bilər.
Güclü tapşırıqlara bəzi nümunələr:
- Gələn həftə Jane ilə ən son Acme Corp layihəmizi müzakirə etmək üçün görüş planla. Son layihə planlaşdırma görüşümüzün qeydlərini əlavə et və konfrans otağı rezerv et.
- Müştəri ID 9182 bir alış cəhdi üçün üç dəfə ödəniş tutulduğunu bildirdi. Bütün əlaqəli log qeydlərini tap və eyni problemdən digər müştərilərin təsirləndiyini müəyyən et.
- Müştəri Sarah Chen ləğv sorğusu təqdim etdi. Saxlama təklifi hazırla. Müəyyən et: (1) niyə ayrılırlar, (2) hansı saxlama təklifi ən inandırıcı olardı və (3) təklif etməzdən əvvəl bilməli olduğumuz risk faktorları.
Və daha zəif tapşırıqlara bəzi nümunələr:
- Gələn həftə [email protected] ilə görüş planla.
purchase_completevəcustomer_id=9182üçün ödəniş log-larını axtar.- Müştəri ID 45892 tərəfindən ləğv sorğusunu tap.
Hər qiymətləndirmə prompt-u yoxlanıla bilən cavab və ya nəticə ilə cütləşdirilməlidir. Yoxlayıcınız həqiqi cavab ilə seçilmiş cavablar arasında sadə dəqiq sətir müqayisəsi kimi sadə, yaxud cavabı mühakimə etmək üçün Claude-u işə cəlb etmək kimi mürəkkəb ola bilər. Formatlama, durğu işarələri və ya etibarlı alternativ ifadələr kimi səthi fərqlərə görə düzgün cavabları rədd edən həddən artıq ciddi yoxlayıcılardan qaçının.
Hər prompt-cavab cütü üçün isteğe bağlı olaraq qiymətləndirmə zamanı agentlərin hər alətin məqsədini dərk edib-etmədiyini ölçmək üçün tapşırığı həll etmək üçün gözlədiyiniz alətləri də təyin edə bilərsiniz. Lakin, tapşırıqları düzgün həll etmək üçün çoxsaylı etibarlı yollar ola biləcəyi üçün strategiyaları həddən artıq təyin etməkdən və ya overfitting-dən qaçınmağa çalışın.
Qiymətləndirmənin icrası
Qiymətləndirmənizi birbaşa LLM API çağırışları ilə proqramatik şəkildə icra etməyi tövsiyə edirik. Sadə agent dövrələrindən (while-dövrələri LLM API və alət çağırışlarını növbələyir) istifadə edin: hər qiymətləndirmə tapşırığı üçün bir dövrə. Hər qiymətləndirmə agentinə tək tapşırıq prompt-u və alətləriniz verilməlidir.
Qiymətləndirmə agentlərinizin sistem prompt-larında agentlərə yalnız strukturlaşdırılmış cavab blokları (yoxlama üçün) deyil, həm də əsaslandırma və rəy blokları çıxarmağı təlimatlandırmağı tövsiyə edirik. Agentlərə bunları alət çağırışı və cavab bloklarından əvvəl çıxarmağı təlimatlandırmaq, düşüncə zənciri (CoT) davranışlarını tetikleyərək LLM-lərin effektiv zəkasını artıra bilər.
Qiymətləndirmənizi Claude ilə aparırsınızsa, oxşar funksionallıq üçün "hazır" olaraq daxili düşüncəni aktiv edə bilərsiniz. Bu, agentlərin niyə müəyyən alətləri çağırdığını və ya çağırmadığını araşdırmağa və alət təsvirləri və spesifikasiyalarında konkret təkmilləşdirmə sahələrini vurğulamağa kömək edəcək.
Üst səviyyə dəqiqliklə yanaşı, fərdi alət çağırışlarının və tapşırıqların ümumi icra müddəti, ümumi alət çağırışlarının sayı, ümumi token istehlakı və alət xətaları kimi digər metrikləri da toplamağı tövsiyə edirik. Alət çağırışlarını izləmək agentlərin izlədiyi ümumi iş axınlarını aşkar edə və alətlərin konsolidasiyası üçün bəzi imkanlar təklif edə bilər.
 Daxili Asana alətlərimizin ayrılmış test dəsti performansı
Daxili Asana alətlərimizin ayrılmış test dəsti performansı
Nəticələrin təhlili Agentlər ziddiyyətli alət təsvirlərindən qeyri-effektiv alət tətbiqlərinə və çaşdırıcı alət sxemlərinə qədər hər şeydə problemləri aşkar etmək və rəy vermək üçün faydalı tərəfdaşlarınızdır. Lakin, nəzərə alın ki, agentlərin rəy və cavablarında nəyi buraxdıqları çox vaxt nəyi daxil etdiklərindən daha vacib ola bilər. LLM-lər həmişə dediklərini nəzərdə tutmurlar.
Agentlərinizin harada tıxandığını və ya çaşdığını müşahidə edin. Kəskin kənarları müəyyən etmək üçün qiymətləndirmə agentlərinizin əsaslandırma və rəylərini (və ya CoT-nu) oxuyun. Agentin CoT-unda açıq şəkildə təsvir edilməyən hər hansı davranışı aşkar etmək üçün xam transkriptləri (alət çağırışları və alət cavabları daxil olmaqla) nəzərdən keçirin. Sətirlərin arasını oxuyun; unutmayın ki, qiymətləndirmə agentləriniz mütləq düzgün cavabları və strategiyaları bilmirlər.
Alət çağırış metriklərınizi təhlil edin. Çoxlu artıq alət çağırışları səhifələmə və ya token limiti parametrlərinin bir qədər düzəldilməsinin lazım olduğunu göstərə bilər; etibarsız parametrlər üçün çoxlu alət xətaları alətlərin daha aydın təsvirlərə və ya daha yaxşı nümunələrə ehtiyacı olduğunu göstərə bilər. Claude-un veb axtarış alətini işə saldığımız zaman, Claude-un alətin query parametrinə lazımsız olaraq 2025 əlavə etdiyini müəyyən etdik ki, bu da axtarış nəticələrini yanlıllaşdırır və performansı aşağı salırdı (alət təsvirini təkmilləşdirərək Claude-u düzgün istiqamətə yönəltdik).
Agentlərlə əməkdaşlıq
Hətta agentlərin nəticələrinizi təhlil etməsinə və alətlərinizi sizin üçün təkmilləşdirməsinə icazə verə bilərsiniz. Sadəcə qiymətləndirmə agentlərinizdən transkriptləri birləşdirin və Claude Code-a yapışdırın. Claude transkriptləri təhlil etmək və bir çox aləti eyni anda yenidən qurmaqda mütəxəssisdir — məsələn, yeni dəyişikliklər ediləndə alət tətbiqlərinin və təsvirlərinin öz-özünə uyğun qalmasını təmin etmək üçün.
Əslində, bu yazıdakı məsləhətlərin əksəriyyəti daxili alət tətbiqlərimizi Claude Code ilə təkrar-təkrar optimallaşdırmaqdan qaynaqlanıb. Qiymətləndirmələrimiz real layihələr, sənədlər və mesajlar daxil olmaqla daxili iş axınlarımızın mürəkkəbliyini əks etdirən daxili iş sahəmiz üzərində yaradılmışdır.
"Təlim" qiymətləndirmələrimizə overfitting etmədiyimizi təmin etmək üçün ayrılmış test dəstlərinə etibar etdik. Bu test dəstləri göstərdi ki, "ekspert" alət tətbiqləri ilə əldə etdiklərimizdən kənarda da əlavə performans təkmilləşdirmələri çıxara bilərik — bu alətlər istər tədqiqatçılarımız tərəfindən əl ilə yazılmış, istərsə də Claude tərəfindən yaradılmış olsun.
Növbəti bölmədə bu prosesdən öyrəndiklərimizin bir hissəsini paylaşacağıq.
Effektiv alətlər yazmaq üçün prinsiplər
Bu bölmədə öyrəndiklərimizi effektiv alətlər yazmaq üçün bir neçə istiqamətverici prinsipə çeviririk.
Agentlər üçün düzgün alətlərin seçilməsi
Daha çox alət həmişə daha yaxşı nəticələrə gətirib çıxarmır. Müşahidə etdiyimiz ümumi bir səhv, alətlərin agentlər üçün uyğun olub-olmamasından asılı olmayaraq, sadəcə mövcud proqram funksionallığını və ya API endpointlərini əhatə edən alətlərdir. Bunun səbəbi odur ki, agentlərin ənənəvi proqram təminatından fərqli "imkanları" var — yəni, onların həmin alətlərlə edə biləcəkləri potensial hərəkətləri qavrama yolları fərqlidir.
LLM agentlərinin məhdud "konteksti" var (yəni eyni anda nə qədər məlumatı emal edə biləcəklərinə dair limitlər var), halbuki kompüter yaddaşı ucuz və boldu. Ünvan kitabında kontakt axtarmaq tapşırığını nəzərdən keçirin. Ənənəvi proqram təminatı kontaktların siyahısını səmərəli şəkildə saxlaya və hər birini növbə ilə yoxlayaraq emal edə bilər.
Lakin əgər LLM agenti BÜTÜN kontaktları qaytaran bir alətdən istifadə edib sonra hər birini token-token oxumalıdırsa, o, məhdud kontekst sahəsini əlaqəsiz məlumatlara sərf edir (təsəvvür edin ki, ünvan kitabınızda hər səhifəni yuxarıdan aşağıya oxuyaraq kontakt axtarırsınız — yəni brute-force axtarışla). Daha yaxşı və daha təbii yanaşma (həm agentlər, həm də insanlar üçün) əvvəlcə müvafiq səhifəyə keçməkdir (bəlkə əlifba sırası ilə tapmaqdır).
Qiymətləndirmə tapşırıqlarınıza uyğun gələn xüsusi yüksək təsirli iş axınlarını hədəfləyən bir neçə düşünülmüş alət qurmağı və oradan genişlənməyi tövsiyə edirik. Ünvan kitabı nümunəsində list_contacts aləti əvəzinə search_contacts və ya message_contact alətini tətbiq etməyi seçə bilərsiniz.
Alətlər funksionallığı birləşdirə bilər, arxa planda potensial olaraq bir neçə diskret əməliyyatı (və ya API çağırışını) idarə edə bilər. Məsələn, alətlər alət cavablarını əlaqəli metadata ilə zənginləşdirə və ya tez-tez zəncirlənən, çoxaddımlı tapşırıqları tək bir alət çağırışında idarə edə bilər.
Budur bəzi nümunələr:
list_users,list_eventsvəcreate_eventalətlərini tətbiq etmək əvəzinə, mövcudluğu tapan və tədbir planlayanschedule_eventalətini tətbiq etməyi düşünün.read_logsaləti tətbiq etmək əvəzinə, yalnız müvafiq log sətirlərini və bəzi ətraf konteksti qaytaransearch_logsalətini tətbiq etməyi düşünün.get_customer_by_id,list_transactionsvəlist_notesalətlərini tətbiq etmək əvəzinə, müştərinin bütün son və müvafiq məlumatlarını birdəfəyə toplayanget_customer_contextalətini tətbiq edin.
Qurduğunuz hər alətin aydın, fərqli bir məqsədinin olduğundan əmin olun. Alətlər agentlərə tapşırıqları bir insanın eyni əsas resurslara çıxışı olduqda edəcəyi kimi bölməyə və həll etməyə imkan verməli və eyni zamanda aralıq nəticələrin tələb edəcəyi konteksti azaltmalıdır.
Həddən artıq çox alət və ya üst-üstə düşən alətlər agentləri səmərəli strategiyalar izləməkdən yayındıra bilər. Qurduğunuz (və ya qurmadığınız) alətlərin diqqətli, seçici planlaşdırılması həqiqətən öz bəhrəsini verir.
Alətlərinizi ad sahəsi ilə qruplaşdırma
Süni intellekt agentləriniz potensial olaraq onlarla MCP serverinə və yüzlərlə fərqli alətə — o cümlədən digər tərtibatçıların alətlərinə — giriş əldə edəcək. Alətlər funksiya baxımından üst-üstə düşdükdə və ya qeyri-müəyyən məqsədə malik olduqda, agentlər hansı alətləri istifadə edəcəkləri barədə çaşa bilər.
Ad sahəsi (əlaqəli alətləri ümumi prefikslər altında qruplaşdırma) çoxlu alətlər arasında sərhədləri müəyyənləşdirməyə kömək edə bilər; MCP müştəriləri bəzən bunu standart olaraq edir. Məsələn, alətləri xidmətə görə (məs., asana_search, jira_search) və resursa görə (məs., asana_projects_search, asana_users_search) ad sahəsi ilə qruplaşdırmaq agentlərin lazımi vaxtda lazımi alətləri seçməsinə kömək edə bilər.
Prefiks- və suffiks-əsaslı ad sahəsi seçimi arasındakı fərqin alət istifadəsi qiymətləndirmələrimizə əhəmiyyətsiz olmayan təsir göstərdiyini müşahidə etdik. Təsirlər LLM-dən asılı olaraq dəyişir və sizi öz qiymətləndirmələrinizə əsasən adlandırma sxemi seçməyə təşviq edirik.
Agentlər yanlış alətləri çağıra, düzgün alətləri yanlış parametrlərlə çağıra, çox az alət çağıra və ya alət cavablarını yanlış emal edə bilər. Adları tapşırıqların təbii bölünmələrini əks etdirən alətləri seçici şəkildə tətbiq etməklə, siz eyni zamanda həm agentin kontekstinə yüklənən alətlərin və alət təsvirlərinin sayını azaldırsınız, həm də agentik hesablamanı agentin kontekstindən geri alət çağırışlarının özünə yükləyirsiniz. Bu, agentin ümumi səhv etmə riskini azaldır.
Alətlərinizdən mənalı kontekst qaytarma
Eyni xətlə, alət tətbiqləri agentlərə yalnız yüksək siqnallı məlumat qaytarmağa diqqət yetirməlidir. Onlar çevikliyə deyil, kontekstual uyğunluğa üstünlük verməli və aşağı səviyyəli texniki identifikatorlardan (məsələn: uuid, 256px_image_url, mime_type) uzaq durmalıdır. name, image_url və file_type kimi sahələr agentlərin sonrakı hərəkətlərini və cavablarını birbaşa məlumatlandırmaq ehtimalı daha yüksəkdir.
Agentlər həmçinin təbii dil adları, terminləri və ya identifikatorları ilə kriptoqrafik identifikatorlarla müqayisədə xeyli daha uğurlu şəkildə işləyirlər. Biz aşkar etdik ki, ixtiyari alfanumerik UUID-ləri daha semantik mənalı və şərh edilə bilən dilə (və ya hətta 0-indeksli ID sxeminə) həll etmək, hallüsinasiyaları azaltmaqla Claude-un axtarış tapşırıqlarında dəqiqliyini əhəmiyyətli dərəcədə yaxşılaşdırır.
Bəzi hallarda agentlər, yalnız sonrakı alət çağırışlarını tetikləmək üçün olsa belə, həm təbii dil, həm də texniki identifikator nəticələri ilə işləmə çevikliyinə ehtiyac duya bilər (məsələn, search_user(name='jane') → send_message(id=12345)). Alətinizdə sadə bir response_format enum parametri təqdim etməklə hər ikisini aktiv edə bilərsiniz ki, agentiniz alətlərin "concise" və ya "detailed" cavab qaytarmasını idarə edə bilsin (aşağıdakı şəkillər).
Daha çox çeviklik üçün daha çox format əlavə edə bilərsiniz, GraphQL-ə bənzər şəkildə hansı məlumat hissələrini almaq istədiyinizi dəqiq seçə bilərsiniz. Budur alət cavabının ətraflılığını idarə etmək üçün nümunə ResponseFormat enum-u:
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}
Budur ətraflı alət cavabının nümunəsi (206 token):

Budur qısa alət cavabının nümunəsi (72 token):
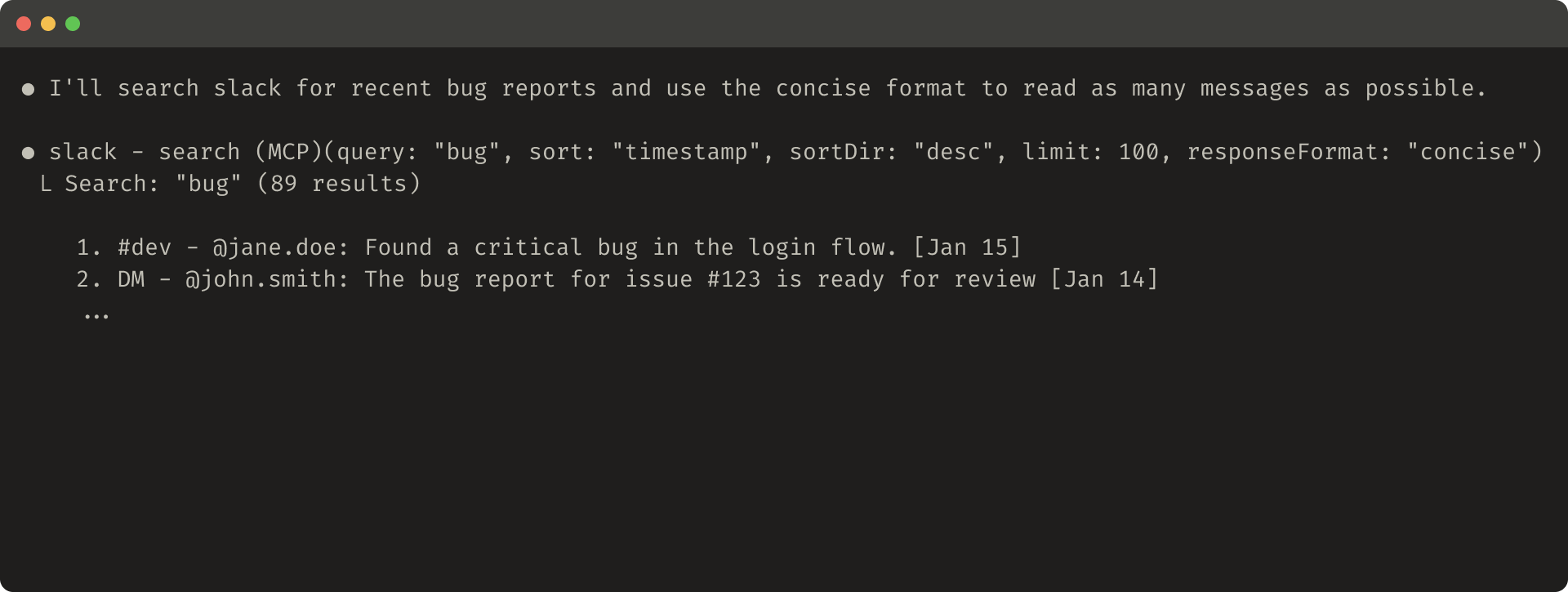 Slack mövzuları və mövzu cavabları unikal
Slack mövzuları və mövzu cavabları unikal thread_ts ilə müəyyən edilir ki, bu da mövzu cavablarını əldə etmək üçün tələb olunur. thread_ts və digər ID-lər (channel_id, user_id) bunları tələb edən əlavə alət çağırışlarını mümkün etmək üçün "detailed" alət cavabından əldə edilə bilər. "concise" alət cavabları yalnız mövzu məzmununu qaytarır və ID-ləri istisna edir. Bu nümunədə "concise" alət cavabları ilə tokenlərin ~⅓-ni istifadə edirik.
Hətta alət cavabınızın strukturu — məsələn XML, JSON və ya Markdown — qiymətləndirmə performansına təsir edə bilər: hər şeyə uyğun gələn tək bir həll yoxdur. Bunun səbəbi LLM-lərin növbəti-token proqnozu üzərində öyrədilməsi və təlim verilənlərinə uyğun formatlarla daha yaxşı performans göstərməsidir. Optimal cavab strukturu tapşırıq və agentdən asılı olaraq çox dəyişəcək. Sizi öz qiymətləndirmənizə əsasən ən yaxşı cavab strukturunu seçməyə təşviq edirik.
Token səmərəliliyi üçün alət cavablarının optimallaşdırılması
Kontekstin keyfiyyətini optimallaşdırmaq vacibdir. Lakin alət cavablarında agentlərə qaytarılan kontekstin miqdarını optimallaşdırmaq da eyni dərəcədə vacibdir.
Çoxlu kontekst istifadə edə bilən hər hansı alət cavabı üçün ağlabatan standart parametr dəyərləri ilə səhifələmə, aralıq seçimi, filtrasiya və/və ya kəsmənin bəzi kombinasiyasını tətbiq etməyi təklif edirik. Claude Code üçün standart olaraq alət cavablarını 25,000 tokenlə məhdudlaşdırırıq. Agentlərin effektiv kontekst uzunluğunun zamanla artacağını gözləyirik, lakin kontekst-səmərəli alətlərə ehtiyacın qalacağını da.
Cavabları kəsməyi seçsəniz, agentləri faydalı təlimatlarla yönəltdiyinizdən əmin olun. Agentləri birbaşa daha token-səmərəli strategiyalar izləməyə təşviq edə bilərsiniz, məsələn bilik axtarışı tapşırığı üçün tək bir geniş axtarış əvəzinə çoxlu kiçik və hədəflənmiş axtarışlar etmək kimi. Eynilə, əgər alət çağırışı xəta verərsə (məsələn, giriş validasiyası zamanı), xəta cavablarınızı qaranlıq xəta kodları və ya geri izləmələr əvəzinə konkret və hərəkət edilə bilən təkmilləşdirmələri aydın şəkildə çatdıracaq formada prompt-mühəndisliyi edə bilərsiniz.
Budur kəsilmiş alət cavabının nümunəsi:

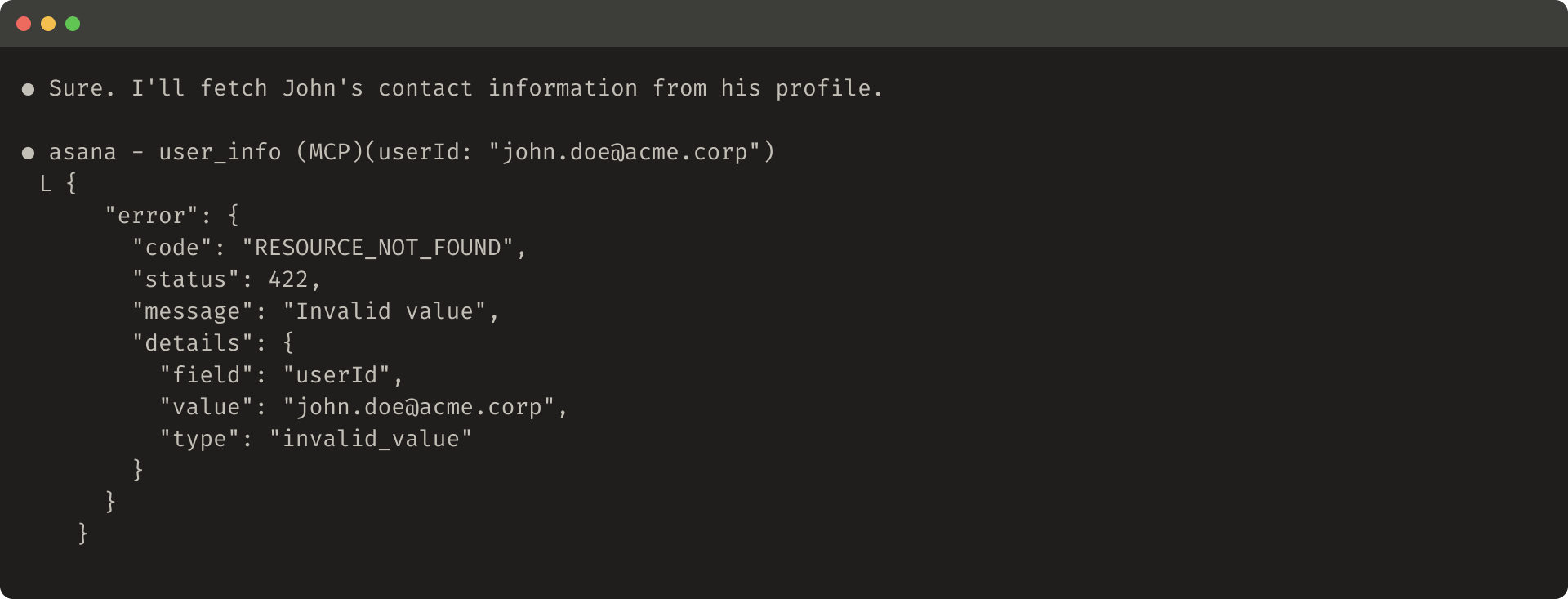
Budur faydasız xəta cavabının nümunəsi:
Budur faydalı xəta cavabının nümunəsi:
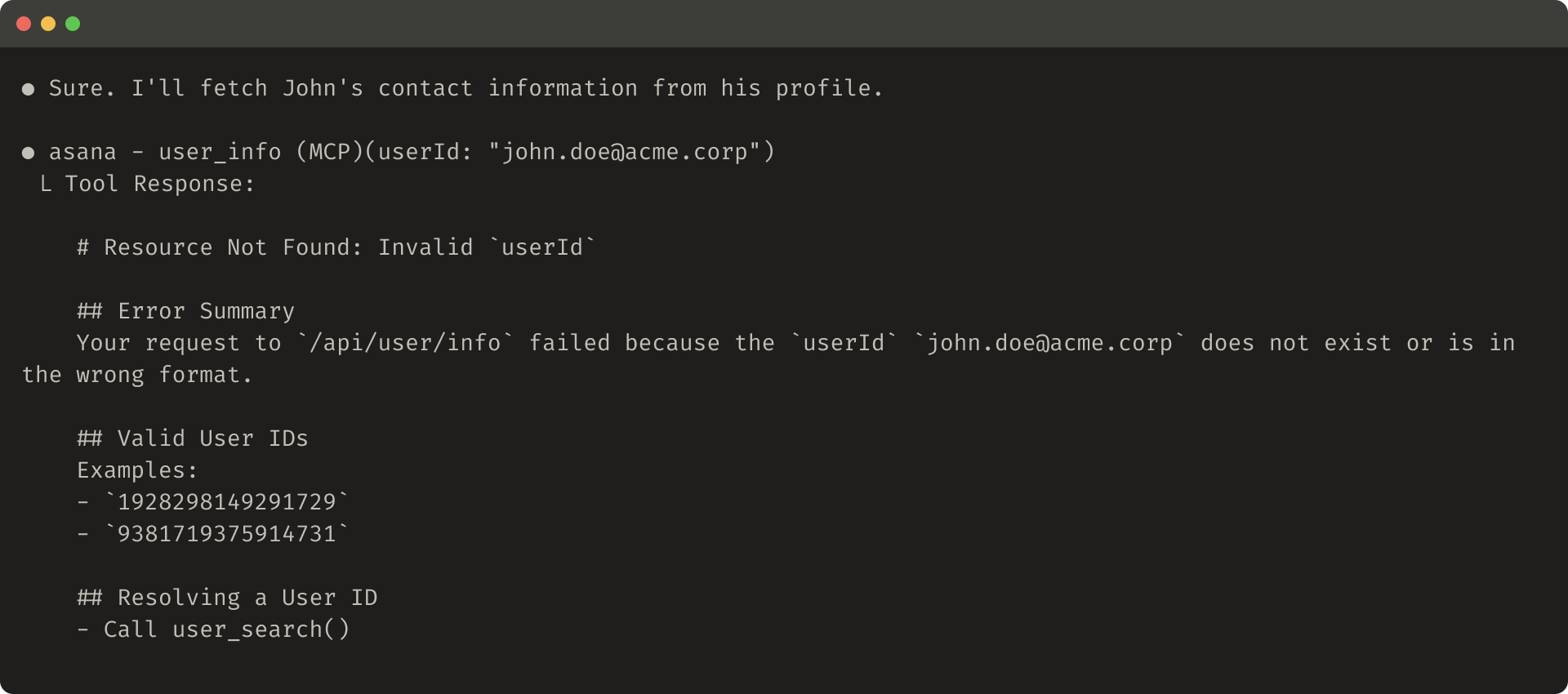 Alət kəsmə və xəta cavabları agentləri daha token-səmərəli alət istifadəsi davranışlarına (filtrlər və ya səhifələmə istifadə etməyə) yönəldə və ya düzgün formatlanmış alət girişlərinin nümunələrini verə bilər.
Alət kəsmə və xəta cavabları agentləri daha token-səmərəli alət istifadəsi davranışlarına (filtrlər və ya səhifələmə istifadə etməyə) yönəldə və ya düzgün formatlanmış alət girişlərinin nümunələrini verə bilər.
Alət təsvirlərinin prompt-mühəndisliyi
İndi alətləri yaxşılaşdırmağın ən effektiv üsullarından birinə gəlirik: alət təsvirlərinizin və spesifikasiyalarınızın prompt-mühəndisliyi. Bunlar agentlərinizin kontekstinə yükləndiyi üçün agentləri kollektiv şəkildə effektiv alət-çağırma davranışlarına yönəldə bilər.
Alət təsvirləri və spesifikasiyaları yazarkən, alətinizi komandanızda yeni bir işçiyə necə təsvir edəcəyinizi düşünün. Dolayısı ilə gətirə biləcəyiniz konteksti nəzərə alın — xüsusiləşdirilmiş sorğu formatları, niş terminologiyanın tərifləri, əsas resurslar arasındakı əlaqələr — və bunu açıq edin. Gözlənilən girişləri və nəticələri aydın şəkildə təsvir edərək (və ciddi verilən modelləri ilə tətbiq edərək) qeyri-müəyyənlikdən qaçının. Xüsusilə giriş parametrləri birmənalı şəkildə adlandırılmalıdır: user adlı parametr əvəzinə user_id adlı parametri sınayın.
Qiymətləndirmənizlə prompt mühəndisliyinizin təsirini daha böyük etimadla ölçə bilərsiniz. Alət təsvirlərindəki hətta kiçik dəqiqləşdirmələr dramatik yaxşılaşmalara gətirib çıxara bilər. Claude Sonnet 3.5, alət təsvirlərinə dəqiq dəqiqləşdirmələr etdikdən sonra SWE-bench Verified qiymətləndirməsində ən yüksək performansa nail oldu, xəta nisbətlərini dramatik şəkildə azaldıb tapşırıq tamamlanmasını yaxşılaşdırdı.
Alət tərifləri üçün digər ən yaxşı təcrübələri Tərtibatçı Bələdçisində tapa bilərsiniz. Claude üçün alətlər qurursunuzsa, alətlərin Claude-un sistem promptuna dinamik şəkildə necə yükləndiyini oxumağınızı da tövsiyə edirik. Nəhayət, MCP serveri üçün alətlər yazırsınızsa, alət annotasiyaları hansı alətlərin açıq dünya girişi tələb etdiyini və ya dağıdıcı dəyişikliklər etdiyini açıqlamağa kömək edir.
Gələcəyə baxış
Agentlər üçün effektiv alətlər qurmaq üçün proqram təminatı inkişaf təcrübələrimizi proqnozlaşdırıla bilən, deterministik nümunələrdən qeyri-deterministik nümunələrə yönəltməliyik.
Bu yazıda təsvir etdiyimiz iterativ, qiymətləndirməyə əsaslanan proses vasitəsilə alətləri uğurlu edən ardıcıl nümunələri müəyyən etdik: Effektiv alətlər bilərəkdən və aydın şəkildə müəyyən edilir, agent kontekstini ehtiyatla istifadə edir, müxtəlif iş axınlarında birləşdirilə bilir və agentlərə real dünya tapşırıqlarını intuitiv şəkildə həll etməyə imkan verir.
Gələcəkdə agentlərin dünya ilə qarşılıqlı əlaqə qurduğu xüsusi mexanizmlərin — MCP protokoluna olan yeniliklərdən tutmuş əsas LLM-lərin özlərinin təkmilləşdirilməsinə qədər — təkamül edəcəyini gözləyirik. Agentlər üçün alətləri yaxşılaşdırmağa sistematik, qiymətləndirməyə əsaslanan yanaşma ilə agentlər daha bacarıqlı olduqca, istifadə etdikləri alətlərin də onlarla birlikdə təkamül edəcəyini təmin edə bilərik.
Təşəkkürlər
Ken Aizawa tərəfindən yazılıb, Research (Barry Zhang, Zachary Witten, Daniel Jiang, Sami Al-Sheikh, Matt Bell, Maggie Vo), MCP (Theodora Chu, John Welsh, David Soria Parra, Adam Jones), Product Engineering (Santiago Seira), Marketing (Molly Vorwerck), Design (Drew Roper) və Applied AI (Christian Ryan, Alexander Bricken) bölmələrindən həmkarların dəyərli töhfələri ilə.
1Əsas LLM-lərin özlərinin öyrədilməsi xaricində.